
外部メトリクスによるK8sのHPA
はじめに
こんにちは、クラウドエンジニアの査です。最近はGCP関連のインフラ、特にGKEやKafkaの構築、メンテナンスと監視周りの業務を担当しています。
本日は、以下の構成図のように、Kafkaから収集したメトリクスを利用して、KubernetesのHPAを制御し、アプリケーションのパフォーマンスを自動的に調整する方法を解説したいと思います。
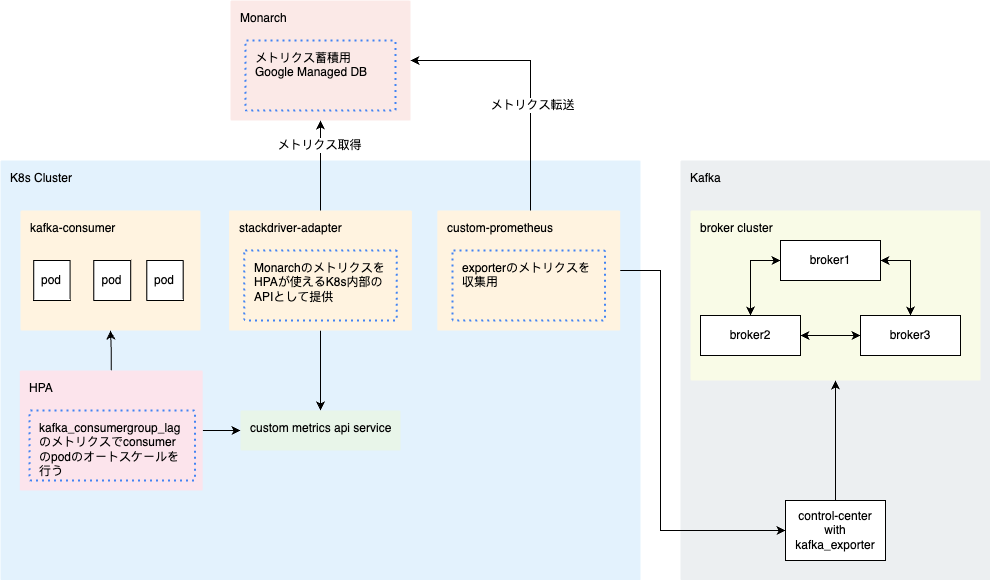
Kubernetesを使用してコンテナ化されたアプリケーションをデプロイする際、アプリケーションの負荷やトラフィックの変動に柔軟に対応できることが重要です。そのために、Kubernetesクラスター内のアプリケーションを自動的にスケーリングできるHorizontal Pod Autoscaler(HPA)というKubernetesの強力な機能があります。
Kafkaは、分散メッセージングシステムとしての優れた性能と信頼性を提供する一方、トラフィックの変動に適応できるスケーリングメカニズムが求められます。
利用した技術の一覧
Kafka_exporter
kafkaクラスターのメトリクスを収集するためのexporter
Custom-prometheus
GKE用prometheusエンジン、デプロイされたexporterからメトリクスを定期的に取得し、Monarchに保存することが可能
Monarch
Monarch は、すべての Prometheus データを 24 か月間、追加費用なしで保存するデータベース
Stackdriver-adapter
カスタム指標をHPAに利用させられるようにするアダプター
HPA
管理対象となるPodの数を、指定したメトリクス(例えばCPU使用率)に基づいて自動的にスケールさせる
実装例と注意点
Kafka_exporter
SystemサービスとしてKafkaクラスターに実装されます。
注意点
- GKEのPodのcidrからのTCPアクセスをFirewallで許可する必要があります(デフォルトのポート: 9308)。
Custom-prometheus
gkeでprometheus-engineを実装し、prometheusのscrape_configsに下記の例のように設定します。
apiVersion: v1
kind: ConfigMap
metadata:
namespace: gmp-public
name: custom-prometheus
data:
config.yaml: |
global:
scrape_interval: 30s
scrape_configs:
- job_name: kafka-exporter
static_configs:
- targets: ['kafka:9308']
custom-prometheusのGUIのstatus → targetで、kafka-exporterのステータスがUPであればOK。

Stackdriver-adapter
注意点
- カスタムAPIサービスを作成するには、Control Planeからstackdriver-adapterからのアクセスが必要なので、Firewall RuleにControl PlaneのcidrからnodeへのTCPアクセス(ポート:443)を許可する必要があります
- stackdriver-adapterはサービスアカウント
custom-metrics-stackdriver-adapterを作成し、利用するが、デフォルトでは権限がないため、403エラーが発生する。解決方法として、custom-metrics-stackdriver-adapterにGCPのサービスアカウント(例えばstackdriver-adapter-wi@<project_id>.iam.gserviceaccount.com)とバインドし、roles/monitoring.viewerの権限を付与します
実装が上手くいけば、以下のとおりにK8sにカスタムAPIサービスが3つ作成されます。
custom.metrics.k8s.io/v1beta1custom.metrics.k8s.io/v1beta2external.metrics.k8s.io/v1beta1
下記のコマンドでカスタムメトリクスのAPIを確認できます。
kubectl get --raw "/apis/<apiservice>" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "<apiservice>",
"resources": [
<MonarchMetrics>
]
}
検証用Deployment
下記のYamlでNamespacekafka-hpaにDeploymentnginxを作成します。
apiVersion: v1
kind: Namespace
metadata:
name: kafka-hpa
labels:
name: kafka-hpa
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: kafka-hpa
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
HPA
Deploymentnginxに対して、外部メトリクスkafka_consumergroup_lag_sumを利用し、1台ごとにconsumer lagが100になったらレプリカ数を最大5台まで増やすように設定します。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: kafka-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 5
metrics:
- type: External
external:
metric:
name: prometheus.googleapis.com|kafka_consumergroup_lag_sum|gauge
selector:
matchLabels:
metric.labels.consumergroup: hpa-group
target:
type: AverageValue
averageValue: "100"
注意点
- 今回はPodに関係のないメトリクスを利用するため、 type: Externalを指定したが、他のtypeの使い方はこちらのドキュメントをご参照ください。
- メトリクスの指定方法は上記のマニフェストを例にすると、metrics[0].external.metric.nameの形式で書くことができます。なお、具体的な使い方はカスタムメトリクスのAPIをご参照ください。
- エクスターナルメトリクスAPIの利用方法について、下記のようにフルパスを指定しないと確認できないので、カスタムメトリクスAPIでメトリクス名を確認する方がおすすめです。
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/kafka-hpa/prometheus.googleapis.com|kafka_consumergroup_lag_sum|gauge" | jq
{
"kind": "ExternalMetricValueList",
"apiVersion": "external.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"metricName": "prometheus.googleapis.com|kafka_consumergroup_lag_sum|gauge",
"metricLabels": {
"metric.labels.consumergroup": "hpa-group",
"metric.labels.topic": "",
"resource.labels.project_id": "",
"resource.type": "prometheus_target"
}
}
]
}
- 上記のAPIで確認した結果、マッチングしたいラベルがあれば、マニフェストの
matchLabelsのように記載すればOK。
検証
HPAの動作確認
KafkaのConsumerGrouphpa-groupのConsumerGroup Lagは0なので、HPAのTARGETSは 0/100 (avg)で、レプリカ数も最小Pod数と同じく1になっています。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0/100 (avg) 1 5 1 3m
Kafka Clusterに10000件のMessageをProduceし、HPA, deploymentの動作確認
HPAのTARGETSは10k/100 (avg)になり、レプリカ数も最大Pod数と同じく5になっています。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 10k/100 (avg) 1 5 5 10m
稼働中のPod数が5になることを確認しました。
kubectl get deployment -n kafka-hpa nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 5/5 5 5 10m
Kafka Clusterから9700件のMessageをConsumeし、HPA, deploymentの動作確認
kafkaに残っているMessage数は300なので、1PodあたりのConsumerGroup Lagは60、HPAのTARGETSも 60/100 (avg)になっています。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 60/100 (avg) 1 5 5 15m
数分後レプリカ数が3になりました。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 100/100 (avg) 1 5 3 20m
稼働中のPod数が3になることを確認しました。
kubectl get deployment -n kafka-hpa nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/3 3 3 20m
Messageを全部Consume
kafkaに残っているMessage数は0なので、1PodあたりのConsumerGroup Lagは0、HPAのTARGETSも 0/100 (avg)になっています。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0/100 (avg) 1 5 3 22m
数分後レプリカ数が1になりました。
kubectl get hpa -n kafka-hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 100/100 (avg) 1 5 1 27m
稼働中のPod数が0になることを確認しました。
kubectl get deployment -n kafka-hpa nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 27m
次のステップ
Kafka Consumerをプロダクション環境で利用する前には、consumerの追加、削除時にpartitionのrebalancingが発生するため、負荷をかけながらHPAのパラメーターのチューニングが必要です。
終わりに
stackdriver-adapter + HPA + Prometheusを使えば、PodのAutoScalingに任意のメトリクスを利用できます。これは、Kubernetesの標準的なHPAでは対応できないカスタムメトリクスや外部メトリクスを活用できるということです。例えば、CPU使用率だけでなく、リクエスト数やデータベースのレイテンシなど、アプリケーションに特化したメトリクスを指定できます。
また、Prometheusはオープンソースのモニタリングツールとして広く使われており、多くのエクスポーターやインテグレーションが提供されています。これにより、様々なシステムやサービスのメトリクスを収集し、HPAに渡すことができます。
stackdriver-adapterは、Prometheusから収集したメトリクスをStackdriverに送信し、HPAがStackdriverからメトリクスを取得する仕組みです。このようにして、stackdriver-adapter + HPA + Prometheusは、PodのAutoScalingに高い柔軟性と汎用性を提供します。これは、Kubernetesのパフォーマンスと信頼性を向上させるために重要な要素です。
このブログでは、この組み合わせの設定方法や動作確認方法を紹介しました。ぜひ参考にしてみてください。
