
外部機能に依存する処理を非同期イベント機構とリトライで解決する
こんにちは、ホシイです 👋
今回は、記事タイトルを見てもぱっとイメージしにくい話題です。ちょっと複雑で、うまく説明できるか自信がないですが、ひとつずつ順を追って書いてみます。
ちなみに (いつもそうですが) 記事の内容は弊社すべてのシステムで採用している技術・ポリシーではなく、ひとつの解決案としてお考えください。
外部 API 呼び出しをするサーバーでのよくある悩み
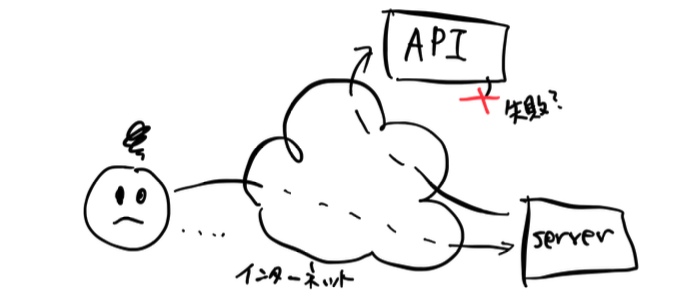
web アプリケーションなどで、リクエストを受けたサーバーがさらに外部の API 呼び出しをすることってよくありますよね。そして、このインターネット時代、そういった API 呼び出しは失敗することもあればタイムアウトすることもよくあります。エラーが返ってきたならまだしも、うまくいったかどうかもわからない場合は、どうしたらいいでしょうか?
今回はここをスタート地点にして、どういった解決が考えられるかを見ていきます。
ちなみに今回の対象は、数百ミリ〜数秒かかるような処理で、比較的時間はかかるがひとつひとつの通信の確実性を重視するもの、典型的には「アプリ内通貨を差し引いてアイテムを得る」ようなものを想定しています。
サーバー通信といっても、より頻度が高く低レイテンシーを要求するリアルタイム性の高いもの (オンラインアクションゲーム等で使用されるもの) もありますが、そういった用途にはまったく別の仕組みが用いられますので、今回の記事では扱いません。
リトライと課題
API 呼び出しが失敗したとき、まず考えられるのはリトライです。network がいつも 100% 完全と言えない以上、リトライすること自体は必須でしょう。しかし、ここでいくつか問題があります。
- API はほんとうに失敗したのか? タイムアウトしていた場合、実は結果が得られていないだけで、API の処理自体は成功しているかもしれない
- この場合、リトライすると、二回 (以上) 操作することになってしまわないか
- リトライするとして、回数とか間隔、契機・トリガー条件はどうしたらいいか
一般的な解決策として、処理の冪等性と exponential backoff があります。ひとつずつ見ていきます。
冪等な処理として実装する (idempotent にする)
API などの機能を実装するとき、おなじ入力であれば複数回呼び出されても一回の実行と結果が変わらないようにします。たとえばあるユーザーのスコアに 300 を足す処理で、リトライしたからといって二回足して 600 になっちゃうとマズイです。
冪等でない処理
- 一回目) user_id 1000 のスコアに 300 を足す → { user_id: 1000, score: 300 }
- 二回目 (リトライ)) user_id 1000 のスコアに 300 を足す → { user_id: 1000, score: 600 }
冪等な処理
- 一回目) user_id 1000 のスコアに 300 を足す → { user_id: 1000, score: 300 }
- 二回目 (リトライ)) user_id 1000 のスコアに 300 を足す → { user_id: 1000, score: 300 }
一見こんな処理を書くのは不可能に思われますが、(例えば) request に ID を振っておくと可能です。server 側で request ID を記録しておき、すでにおなじ request が完了していたことが確認できたら、処理を継続せずに単に OK status を返すように実装します。
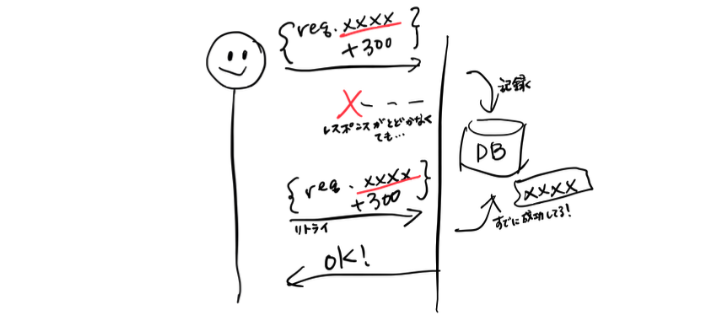
これにより、結果が得られずに成功したかどうかわからない場合でも、成功が確認できるまで何度でもリトライが可能になります。
リトライ間隔に exponential backoff を入れる
無制限なリトライを実装すると、たとえば network の調子が少し悪くなったときなどに、ひとつひとつのリクエストに対するリトライ回数が増え、システム全体でのリクエスト数を爆発的に増加させる結果になります。これは network 帯域をはじめシステムのリソースを逼迫し、全体的な安定性をさらに下げる悪循環に陥ってしまいます。
これを避けるために、リトライロジックには「最大リトライ回数を制限する」のと「次のリトライまでの時間間隔を指数的に延ばす」処理を実装します。
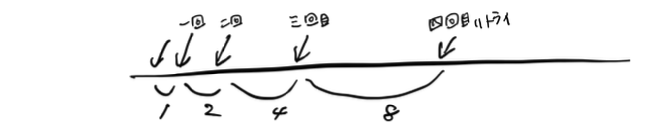
こちら にアルゴリズムの例がありますが、リトライ回数が重なるに伴って 1、2、4、のように指数関数的に次のリトライを遅らせます。これにより、障害が起きたときに一気に全体のリクエスト数が増えてしまうことを防ぎます。また、リンク先の例ではジッタ (ゆらぎ) も追加しています。問題がおきたタイミングで発生した多くのリトライが同期して波のように発生すると結局負荷が集中してしまうため、これもとても有効な仕組みです。
さて、これらの仕組みによって、成功が確認できるまでリトライするという作戦ができました。しかし、エンドユーザーの操作が契機のリトライだけでは、確実な完了を期待できません。クライアントがモバイルアプリである場合などでは、データ破損によるアプリ動作不備等でリトライがしたくてもできないといったことも考えられるでしょう。
リトライの主体を変える
リトライ自体は安全にできるようになったとして、次は誰がリトライを行うかを考えます。
リトライを誰に任せるか
エンドユーザーから直接呼び出される API が、さらにその先の連携 API を呼び出すとき、それを API 内部でリトライするようにしていると、結果が確定するまでに長い時間がかかることになります。上記のように backoff を仕込むと、その時間は数十秒程度になります。これをユーザーに待たせるのは現実的ではないので、こういった時間がかかることが想定される処理は最初から非同期実行にしておいたほうがよいかもしれません。
具体的には、処理自体をリクエストするのではなく、最初のリクエストでは処理実行開始を要求し、後でその結果を問い合わせる (もしくは結果が通知される) ようにします。また、しばらく後で結果を問い合わせしたときにはじめて失敗していることがわかってリトライする、ではまた時間がかかってしまうので、リトライはサーバー側で自動的に行うようにします。
しかし、API サーバーのようなもので数秒間の backoff つきリトライを仕込んでしまうと、sleep ばかりで何もしない処理がたくさん蓄積してしまい、worker が専有されてしまいます。(そうなりにくいように thread を使わず event/poll のような実装も使えるでしょうが、自前で実装するのはちょっと手間です) そこで、独立した Messaging 機構を使って処理を非同期化します。
Messaging にリトライをオフロードする
ここで Messaging と言っているのは Apache Kafka や Google Cloud Pub/Sub のような、システムの非同期化などを目的として message を送信・受信するための中間を取り持つサービスです。Event Stream とか Message Queue と説明されていることもあり、そちらのほうが一般的かもしれません。
Google Cloud Pub/Sub などでは、message を受け取る側が ack を返すまでは message を保持しておき、あらかじめ設定したタイミングで再送してくれる機能があります。しかも、先に説明した exponential backoff つきです。これを利用すると、処理開始要求が来たらとりあえず message を送信しておく → message handler で実際の処理をする → 失敗するなりしたら Pub/Sub が message を再送してくれる → 成功したら ack して message を削除する → 終了 というフローができます。
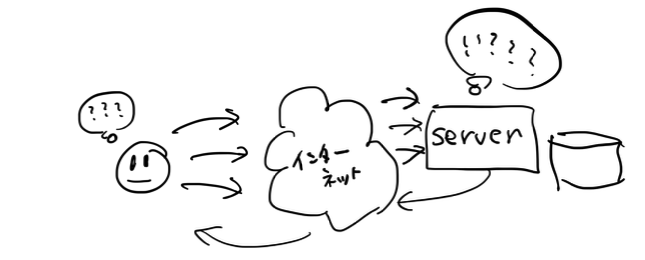
少しだけややこしくなったので、絵にしてみます。
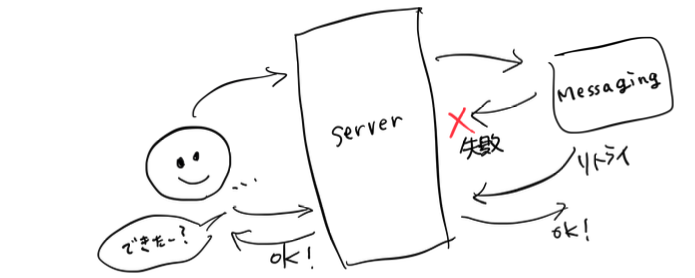
うーん、これでどうでしょうか。
試してみよう
かんたんに動作が確認できるように・かつ実装のサンプルになるように、Spring Boot と、「Messaging といえば」くらいよく使われている (個人の印象) Apache Kafka を用いてお試し実装をしてみました。そこで気づいたのですが、… Kafka って個別 message の再送の機能が無いのでしょうか…? 受け取りのマーカー (オフセット) を進めずに再実行することによりおなじ message を複数回受け取ることはできますが、それだと batch 処理的な動作になってしまい、streaming 的な処理ができません。
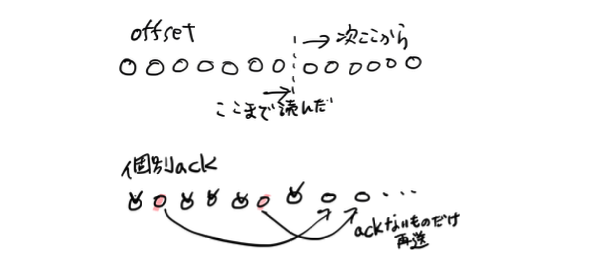
確認したところ、Kafka と似た機能を提供する Apache Pulsar では message ごとの再送も可能なようでしたので、こちらで試してみます。名前に使われている pulsar は周期的に電磁波を放つ天体のことだそうで、まさに今使おうとしているような messaging の機能を連想させます。
Pulsar は公開されている container image を利用しました。Docker compose であれば、以下のようなかんたんな記述で起動します。
services:
pulsar:
container_name: pulsar1
image: apachepulsar/pulsar:3.3.0
command: sh -c "bin/apply-config-from-env.py conf/standalone.conf && bin/pulsar standalone"
初期設定値の調整やデータの永続化などを考えるともっといろいろ書くことはあります。詳細は こちら などを参照ください。
Spring Boot での実装は document や例が多くなく、結構試行錯誤しました。参考までに抜粋を載せておきます。(import 文などは省いています)
// message 再送に exponential backoff を入れるための計算ロジックです.
@Configuration
class AppRedeliveryConfig
{
@Bean
RedeliveryBackoff appDefinedRedeliveryBackoff() {
return MultiplierRedeliveryBackoff.builder()
.minDelayMs(1000).maxDelayMs(30 * 1000).multiplier(2)
.build();
}
}
@Service
@EnablePulsar
class MessageConsumerService {
private static final Logger logger = LoggerFactory.getLogger(MessageConsumerService.class);
// message の受信によってこの method が呼び出されます.
@PulsarListener(subscriptionName = "sub1", topics = "topic1",
subscriptionType = SubscriptionType.Shared,
negativeAckRedeliveryBackoff = "appDefinedRedeliveryBackoff",
ackTimeoutRedeliveryBackoff = "appDefinedRedeliveryBackoff",
ackMode = AckMode.MANUAL)
void listen(Message<String> omsg, Acknowledgement ack) {
logger.info("Received message {}({})", omsg.getValue(),
omsg.getRedeliveryCount()); // 再送カウントが取れて便利!
// omsg.getPublishTime() // publish された日時も取得できます
// ※ ここでアプリケーションのメイン処理をする
ack.acknowledge(); // これにより message は再送されなくなる
// ack.nack(); // 再送してもらいたいときは negative ack する (または何もせず timeout にまかせてもよい)
}
}
application.properties に Pulsar の接続先を書いておきます。
spring.pulsar.client.service-url=pulsar://pulsar1:6650
今回は gradle を使っています。追加した設定 (依存) は以下のひとつだけです。
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-pulsar'
}
これだけで Pulsar の message streaming を処理する application が書けるのは、かなりお手軽ですね。しかも exponential backoff を入れやすい仕組みまで整っています!
(今回は調べる・試行錯誤に結構時間使いましたが)
俯瞰してみよう
ここまでで、複数システムに連携する実装を一通り眺めてみました。俯瞰してみると、基本の動作としては「成功するまでリトライするのをやめない」だけであり、そのために冪等性や exponential backoff、messaging の導入をしました。
これにより、時間はかかるけどそのうちデータは整合する、いわゆる結果整合を目指す動作ができたとも言えます。
複数システム連携における整合性維持の話題では サーガ (Saga) パターンというものがあり、今回の内容はそれに近いものです。web などでも Saga の説明は多いですが、リトライ戦略や機能内容など、より具体的なことと組み合わせて触れられていることが少ないように感じられたので、今回は記事ではそういった流れも入れてまとめてみました。
ということでようやくいったんのゴールに至りました。
未解決の問題
ここまでの議論では解決していないいくつかの点について触れておきます。
- Isolation - 一連の処理が完了するまでは、部分的に処理が完了している時間 (いわゆる不整合な状態) が発生します。これが問題になることを避けるよう、アプリケーション的な手当が必要なことがあります。(たとえば残高を使って対価を得るような場合、対価付与までは残高が減っただけに見えてしまう等)
- Rollback - 連続する処理のうち、途中まで成功したがその先で回復できないエラーに陥った際、それまでに成功した処理を取り消したくなるかもしれません。仕様によっては実装可能で、人手による運用を減らすために自動処理を実装するのは非常に有効です。ただしその実装は難しくなる傾向があり、念入りな設計・検証が必要です。
- Monitoring・Operation - 最後まで処理完了しないまま残ったものがないかを常時監視しておく必要があります。残ってしまったものがあれば漏らさず検出して再処理に流したり、最終的には人手による回復をします。これはユーザー端末からのリトライ方式であっても同じ課題があり、リトライが message としてサーバー側に残っているぶん状況がわかるだけまだマシとも言えます。
このように、今回のような仕組みが必要ない単純なシステムに比べて、対応が必要なことが増えていることがわかります。
まとめ
複数のシステムが連携する部分の実装について、ひとつの解決策を模索してみました。都度要件や機能は異なるので、それに応じて検討が必要です。かたや、冪等性や exponential backoff は基礎的な仕組みなので、多くの場所で応用がききそうです。
あと本筋とは関係ないのですが、Google Cloud Pub/Sub ってもしかしてとても優れているのでは…? pull 型の subscribe に加えて push 型も可能、今回の記事の要点である再送と exponential backoff にはもちろん対応、他 GCP 機能との連携などの付加機能もあり、スケーリングも自動でインフラの面倒を見る必要がない managed service。もっと宣伝してもいいかもと思いました。じゃっかんお高い印象はありますが 😇
(逆に、Kafka を中心に使われているかたには実は今回の話って通じにくいのかも…? ということに気づきました)
参考
- saga 分散トランザクション パターン | Microsoft Lean
- マイクロサービスアーキテクチャ 第2版 (書籍)
- 6章 ワークフロー にて、microservice においての 2PC と Saga について説明されています。
- Microservice and Transaction Management3 : 合意理論からみる2Phase CommitとMicroservice
- XA transaction (MySQL) https://dev.mysql.com/doc/refman/8.0/ja/xa.html
- 複数の transaction をまとめて管理する標準である XA transaction を、MySQL は support しています。
今回の記事では意見・解釈が異なる部分があるかもしれませんが、以上ほか多々参考にさせていただきました。
