
Graph database に馴染んでみよう
Spanner が Graph database に対応 したというのを見て、では何ができるのか… とすこし考えていました。
わたし自身は IT エンジニアの区分であり数学の素養はからっきしなのですが、AI エンジニアやデータサイエンティストのお仕事はスムーズにサポートできるようにしておきたいと思っています。Graph database が必要な業務に対して迅速にサポートできるように、日頃から馴染んでおくことが大切に思いましたので、今回はその環境をつくって触ってみるところまでをやってみます。
Spanner が対応したとはいえ、emulator にその機能がついているかはパッとわからなかったので、他で世間一般によく使われていそうなものを探してみました。Spanner 自体は費用がかかることと、Spanner そのものの特徴も混ざってくるように感じられたので、今回は graph DB に特化した他のものを使ってみます。
以下あたりの情報がとっつきやすそうに感じられました。Google Cloud の記事ですが、すこし前のもので Neo4j という database を使用しています。
- Neo4j と Google Cloud Vertex AI でよりスマートな AI 向けのグラフを使用する
- Vertex AI samples > neo4j/graph_paysim (Jupyter Notebook)
Graph DB を体験するところまでなら、この手順に従って local に閉じて費用を気にせず実施できそうです。
上記 GitHub に置かれている Jupyter Notebook (.ipynb) の手順をなぞっていきますが、今回は local で手早く済ませるため Notebook ではなく python を直接使用します。
とりあえず環境をつくる
いつもながら Visual Studio Code の Dev Container 機能を使用します。他の環境をご利用の方はお手数ですが、以下の構築手順を参考にして環境構築してください。
このブログでは他にも Dev Container に関する記事 があります。Dev Container って何? と思われたかたにもご覧いただけたら幸いです。
Dev Container 用の設定をつくります。
{
"name": "Test Neo4j",
"dockerComposeFile": "compose.yml",
"service": "client",
"workspaceFolder": "/workspace",
"features": {
"ghcr.io/devcontainers/features/docker-outside-of-docker:1": {}
}
}
services:
client:
container_name: client
image: mcr.microsoft.com/devcontainers/python:3.12-bookworm
tty: true
volumes:
- ..:/workspace:cached
neo4j:
container_name: neo4j
# 手順で使う dump file は 5.x 系に互換性がないようなので 4.x 系を使います
image: neo4j:4.3.22
platform: linux/x86_64 # 4.3.24 は aarch64 が無い
environment:
NEO4J_AUTH: "none"
# plugins を有効にする
# https://neo4j.com/labs/apoc/4.1/installation/#docker
# https://neo4j.com/docs/graph-data-science/current/installation/installation-docker/
NEO4J_apoc_export_file_enabled: "true"
NEO4J_apoc_import_file_enabled: "true"
NEO4J_apoc_import_file_use__neo4j__config: "true"
NEO4JLABS_PLUGINS: "[ \"apoc\", \"graph-data-science\" ]"
ports:
- "127.0.0.1:7474:7474"
- "127.0.0.1:7687:7687"
volumes:
- ../neo4j/data:/var/lib/neo4j/data:cached
- ../neo4j/plugins:/var/lib/neo4j/plugins:cached
また Neo4j のデータを置く folder を作成しておいてください。構成は以下のようになります。
workspace/
├─ .devcontainer/
│ ├─ devcontainer.json
│ └─ compose.yml
└─ neo4j/
├─ data/
└─ plugins/
VS Code で Dev Container を起動すると、Docker Compose により container がふたつ起動します。
ブラウザで localhost:7474 にアクセスすると、Neo4j の web UI にアクセスできます。認証を無しに設定していますので必要に応じて compose.yml で調整してください。
うまく起動しないようであれば docker logs neo4j などで Neo4j container の様子を見てみてください。
Neo4j にデータを import する
上記参照先の手順に従い https://storage.googleapis.com/neo4j-datasets/paysim.dump を download して使います。このデータは、Kaggle | Fraud Detection on PaySim Dataset を調整したものだそうです。IT エンジニアとしてはデータを準備する段階も業務の重要な部分を占めるので、ここでどういった調整をしているか調べておくのも参考になりそうです。(今回は省きます)
dump file を download したら、 neo4j container に持っていき、neo4j-admin を使って load します。
$ docker cp ./paysim.dump neo4j:/tmp/
$ docker exec -it neo4j bash
# neo4j-admin load --from=/tmp/paysim.dump --database neo4j --force
Selecting JVM - Version:11.0.21, Name:OpenJDK 64-Bit Server VM, Vendor:Eclipse Adoptium
Done: 115 files, 1.008GiB processed.
load しただけでは Neo4j からデータが見えるようにならないので、Neo4j を再起動します。このために volume などを使って data directory の内容を維持しておく必要があります。上記の compose.yml ではその設定を入れていますが、別の方法で環境構築されているかたはご注意ください。
$ docker restart neo4j
Neo4j の container image では、以下のように /var/lib/neo4j/data が /data へ symlink されており、おなじものを指している状態になっています。また、 $NEO4J_HOME が /var/lib/neo4j に設定されていて、この path を基準として動作する想定のようです。
# ls -dl `pwd`/data /data
drwxr-xr-x 4 neo4j neo4j 128 Aug 9 00:54 /data
lrwxrwxrwx 1 neo4j neo4j 5 Dec 14 2023 /var/lib/neo4j/data -> /data
Python 環境の準備
Jupyter Notebook の代わりにする Python 環境 (client container) にて必要なものを install しておきます。
pip install --upgrade graphdatascience==1.0.0
Numpy 2.x 系は Python 3.12 との相性問題があるようなので、version を下げておきます。
pip install numpy==1.26.4
見てみる
ここまでで環境は構築できたので、すこし動かしながら見てみましょう。
Neo4j web UI
ブラウザからの UI ( localhost:7474 ) は非常に直感的で、query 結果を視覚的に表現することにより感覚をつかみやすくなっています。
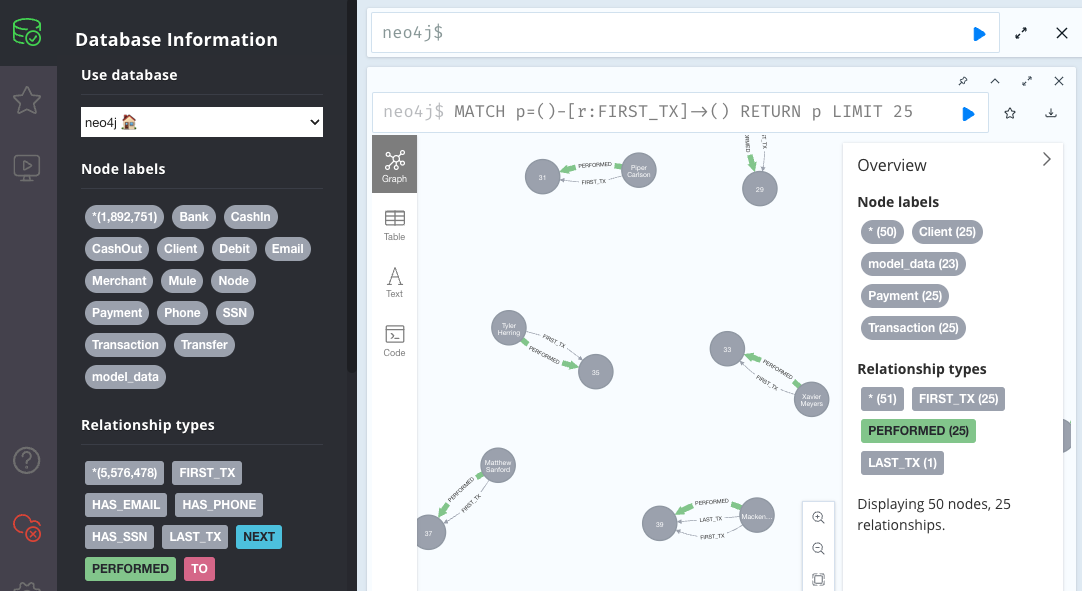
ここで上記画像にも現れていますが、独特な query 言語が使用されています。
MATCH p=()-[r:FIRST_TX]->() RETURN p LIMIT 25
Graph DB の要素は node と edge でできています。上記 query では FIRST_TX で接続された node を 25 件を上限に返します。 ()-[r:FIRST_TX]->() という書き方はよく見ると直感的ですね。
Neo4j では Cypher という query 言語を使用しているようですが、GQL という ISO によって標準化された言語もあるようで、Spanner はそちらを使用するようです。GQL は Cypher を元にはしているようですが、どのくらいの差異があるのかまでは調べていません。
ところで GraphQL は用途がまったく別で API のためのものであり、名前も含めてちょっとややこしいですね。
サンプルコード
環境ができたので、 最初にあげた Notebook のコード を実行していきます。ここではすべてを引用はせず、特徴的な部分のみ抜粋します。
接続は local 環境に合わせて、以下のようにしておきます。
DB_URL = "neo4j://neo4j"
DB_USER = "neo4j"
DB_PASS = "YOUR PASSWORD"
DB_NAME = "neo4j"
もともとの dataset が不正利用の transaction を探してみようという趣旨のものであり、このサンプルでもそれを目的として query をしています。
G, results = gds.graph.project.cypher(
"client_graph",
"MATCH (c:Client) RETURN id(c) as id, c.num_transactions as num_transactions, c.total_transaction_amnt as total_transaction_amnt, c.is_fraudster as is_fraudster",
'MATCH (c:Client)-[:PERFORMED]->(t:Transaction)-[:TO]->(c2:Client) return id(c) as source, id(c2) as target, sum(t.amount) as amount, "TRANSACTED_WITH" as type ',
)
取得したデータに対し、FastRP (Fast Random Projection) algorithm を使用して embedding を計算し、結果を node property として保存しています。
results = gds.fastRP.mutate(
G,
relationshipWeightProperty="amount",
iterationWeights=[0.0, 1.00, 1.00, 0.80, 0.60],
featureProperties=["num_transactions", "total_transaction_amnt"],
propertyRatio=0.25,
nodeSelfInfluence=0.15,
embeddingDimension=16,
randomSeed=1,
mutateProperty="embedding",
)
要するに必要な情報を取得してそれに embedding を追加し、ML タスクに使用できるようにしているということでしょう。
このあとはここまでで作成したデータを csv に保存しています。
$ head features.csv
nodeId,embedding_0,embedding_1,embedding_2,embedding_3,embedding_4,embedding_5,embedding_6,embedding_7,embedding_8,embedding_9,embedding_10,embedding_11,embedding_12,embedding_13,embedding_14,embedding_15
0,0.0,-3.641206660631724e-07,0.0,0.0,-3.641206660631724e-07,-3.641206660631724e-07,3.641206660631724e-07,3.641206660631724e-07,3.641206660631724e-07,0.0,0.0,0.0,-0.0749993696808815,-0.07500189542770386,0.0749993696808815,0.0749993696808815
5,0.02352503128349781,-0.023524967953562737,2.529249476523887e-09,5.642404232730769e-08,-0.02352495677769184,-6.034454003156497e-08,-3.0876390333389736e-09,0.02352495864033699,-6.277139918964281e-11,-5.563631333416197e-09,-1.257205228810676e-09,-6.579878686352458e-08,-1.7745630741119385,-1.7745740413665771,1.7745630741119385,1.7745630741119385
10,0.0,0.0,-0.06708204001188278,0.0,0.0,-0.06708204001188278,0.06708204001188278,-0.06708204001188278,0.0,0.06708204001188278,0.0,0.0,0.0,0.0,0.0,0.0
サンプルでは、このあとこの csv を Vertex AI Feature Store に送り、model の train に使用し、それを用いて predict まで行うようです。…が、今回の記事にはじゅうぶんな余白 (体力ともいう) が無いのでここまでにします。機会があればまた別で…
まとめ
最近聞くことも多くなったように感じる、graph database について触ってみました。これで急に「ちょっと環境つくりたいんだけど?」と言われても会話についていくことくらいはできるかもしれません。
Cypher を眺めてみて、RDBMS/SQL の目的とはかなり違いがあることがわかりました。このようにしてデータから意味合いのようなものを探すのですね。
こういった備えにより、ビジネスの道しるべとなるデータサイエンティストのお仕事をスムーズにサポートできたらと思います 🤗
参考
- Neo4j Graph Data Science Library(GDS)の紹介 #Neo4j | クリエーションライン Tech Blog
- Graph Data Science Library を利用した fraud detection の例
- Vertex Feature Storeの機械学習システムへの導入 | ZOZO TECH BLOG
- Vertex AI Feature Store の試用感と課題、代替として OSS である Feast にも触れている
