
TiDBワークショップ『TiDBエキスパートへの道』に参加してきました!
はじめに
スクウェア・エニックスでSREをしている伊賀といいます。 今回PingCAP様主催のTiDBワークショップに参加してきたので、TiDBの概要と魅力についてお伝えしたいと思います! PingCAP様の公式ページにもTiDBの紹介や事例等の掲載がありますので興味があれば是非!
https://pingcap.co.jp/ PingCAP様公式ホームページ
https://pingcap.co.jp/event/workshop/ TiDBエキスパートへの道:実践的な知識とPingCAP認定のスキルアップワークショップ
TiDBを一言で表すと「MySQLと高い互換性があり、オンラインでScale可能で、OLTPとOLAPも任せられるNewSQL」です。 もう少し言うとMySQLとの高い互換性による移行の容易性、高いScalabilityによる耐障害性、そしてコストメリットを得られる理想的なDatabaseだと考えています。
TiDBのアーキテクチャー
今回のワークショップではTiDBの基本的な構成要素をハンズオン形式で学ぶことができました。 TiDBは基本的にMySQL互換ですが、内部的には分散アーキテクチャーを採用しています。大きく分けるとSQL実行計画の生成と、SQL実行を担うTiDB Server、ストレージレイヤーであるTiKV、そしてOLAP系の処理を担うColumnar DatabaseのTiFlashが存在します。(Metadata管理を担うPD Serverの説明は割愛)。
この構成によって今までのDBでなかなか難しかったScalabilityを確保し、かつOLAP系の処理もアプリケーションが意識することなくTiKVとTiFlashが適切に分担して高速に処理し結果を返すというアーキテクチャになっています。
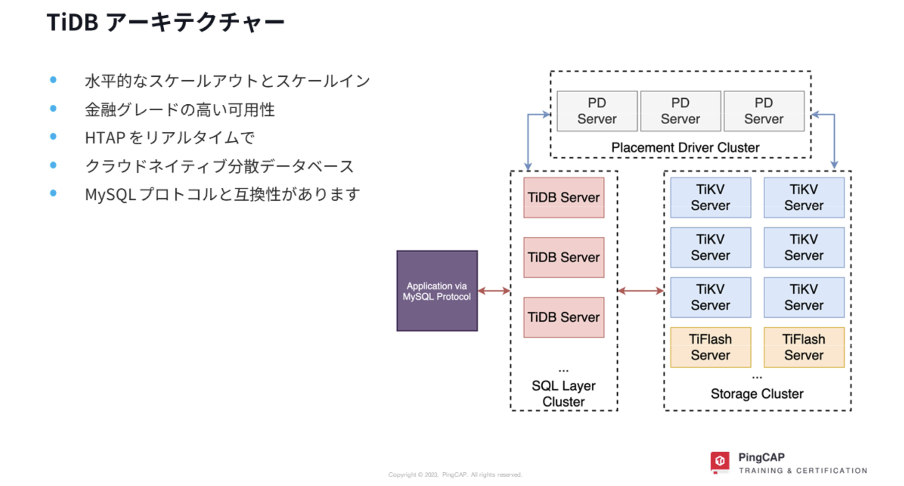
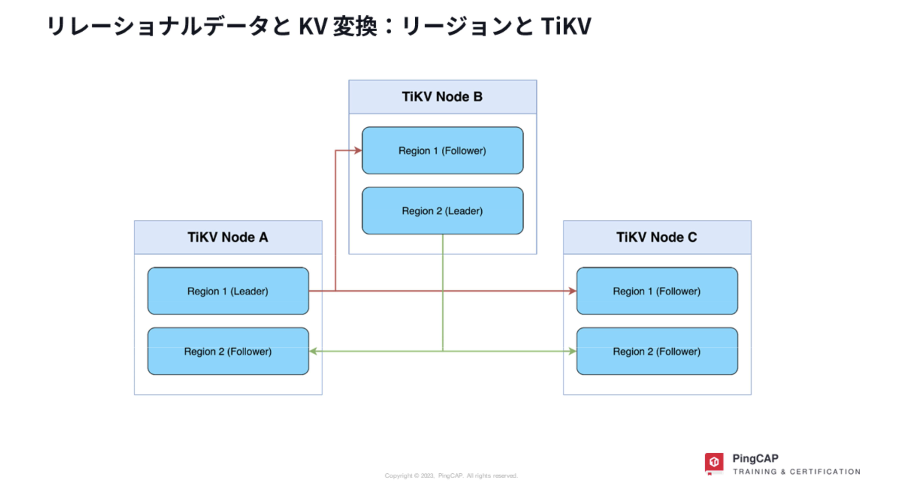
また、ストレージレイヤーを担うTiKVの実態はKey-Value型となっており、各ノードにデータを分散して持つため高い耐障害性とメンテナンス時も zero-downtimeでupgrade可能といった特徴を持っています。 ※図内に書かれている「リージョン」はデータ管理の単位であり、クラウドでよくある「地域」という意味ではありません
TiDBは私達が抱える課題・辛さを解決できるか?
ゲーム特有のワークロードに対する悩みもありますが、それだけではなくDatabaseを運用していると誰もが遭遇する辛さを私も抱えています。
- ピーク時にあわせたスペック設計による平常時のリソースの無駄
- 異なるワークロード、運用のためのReplicaが多い、これもリソースの無駄
- OSやMySQL自体のバージョンアップや構成変更による計画停止
TiDBならその課題全部解決できます!(と私達は信じています!)
1.ピーク時にあわせたスペック設計による平常時のリソースの無駄
TiDBはオンラインでNodeのScale Out/In・Up/Downが可能です。アプリケーションの処理に影響を与えず可能です。適切にScaleさせるにはDBへの負荷が予測可能であるという前提ですが、ピーク時の負荷が平常時の100~1000倍になるようなワークロードのDBに対しては、これだけでかなりのコストメリットが出ると思います。
2.異なるワークロード、運用のためのReplicaが多い、これもリソースの無駄
次に2つめの辛さです。OLTP用、OLAP用、backup用、分析用、、と影響の分離や異なるワークロードに対してReplicaを用意し、急激にサーバー台数が増えていく状態を経験しています。一定のReplicaを利用したある程度の分離は安定運用のためには欠かせないのですが、基本的に増加していく一方で、必要に応じて統合していくというのはコストもかかるし減らして大丈夫かの試験なんてやってる暇ないですし、、、現実的にはとても難しいですよね。 TiDBでは1セットでいけます!
3. OSやMySQL自体のバージョンアップによる構成変更による計画停止
TiDBはバージョンアップもオンラインでできちゃいます。分散アーキテクチャーだからこそできる、ローリングによるアップグレードですね。何よりそのシステムを使うユーザー、別システムに対してサービス利用不可の時間を低減することができ、ビジネスの機会損失を最小限にすることができると思います。toCであったり24✕365のシステムなら喉から手が出る特徴なのは勿論なのですが、停止可能なシステムにおいてもアップグレードの敷居がかなり低くなるので検討の余地はあると思っています。
どこにでもある課題ですがTiDBならまるっと解決できそう、、、、というのが今私達が考えていることです。
TiDBを使うために超えないといけない壁
ここまでTiDBを褒めちぎってきたわけですが、MySQLからTiDBに移行するときに壁がないわけではありません。恐らく、分散アーキテクチャによるパフォーマンスの問題が大きく立ちはだかると思っています。
例えば、よくあるテーブル設計としてAUTO INCREMENTを利用したPKを持つことはあるかと思います。しかし、そのままTiDBで利用した場合には前述のデータの持ち方に起因して、当該テーブルへの書き込みは特定リージョン(TiKVでのデータ管理単位)に負荷が偏る、すなわち書き込み時のHotspotを誘発しパフォーマンスが落ちるという特性もあったりします。
また、TiKV内部ではPK以外のIndexとテーブルデータに対して、KVレコードをそれぞれ別に持ちます。したがってパフォーマンスの観点では、Indexを経由することで読み取りコストが増えてしまわないように、PK以外のIndexを利用しないで済む設計をするほうが望ましい気がします。また、ストレージの観点ではIndexを極力利用しないほうが余計なKVレコードを持たないで済みます。
これらのことから、特にTiDB自体のアーキテクチャーを理解したうえでSQLの調整をしていったほうが良さそうという印象です。 予想するにスペックや台数でお茶を濁せる場面もあるとは思いますが、コスパよくTiDBを使っていくためには検証必須だと考えています。
ただ、TiDBに内包されているKey Visualizer機能があるようなのでこれを駆使して解決していくことになると考えていたり、今後大きな流れの1つになっていくと思われる分散系DBの細かいアーキテクチャーをキャッチアップするのは自分の価値を高められると前向きにも考えています。
まとめ
TiDBを採用する壁はあるものの適切なSQL設計を行えば、高い可用性と耐障害性、並びに大きなコストメリットを得られる次世代のデータベースだと感じました。 まさしく『New SQL』だと考えています。 そしてワークショップに参加することで詳細な内部の技術的な解像度が高まり、もっと知りたい、検証してみたい!という気持ちになりました。
