
GCP Logs-based Metrics を活用して API call dashboard をつくる
log を活用してシステムの可視化を進める
今回は Observability に関連する記事です。Observability といえば、以前にも custom metrics や trace を送信する方法を調査しました。
今回は「アプリケーションに手を入れるのはしんどいのだが、log にはすでにある程度の情報を吐いているので、それを活用してシステムの可視化ができないだろうか」というシナリオを想定してできることを見てみます。
GCP では Logs-based metrics という機能がありまして、かんたんに言うとこれを使ってみましょう、という内容です。
前提として、GCP Operations Suite (旧 Stackdriver) に log を送信していることとします。
Logs-based metrics を設定してみる
今回は、API サーバーが以下のような log を出力している想定としましょう。
2022/03/15-09:30:41 - API call [sqex.api.user.readInfo] -
2022/03/15-09:30:42 - API call [sqex.api.user.readInfo] -
2022/03/15-09:30:43 - API call [sqex.api.user.writeInfo] -
httpd でいう access_log のようなもので、日時と実行した API 名を log に出しています。一般的に、こういったものを出力するのはよくあることだと思います。
上記リンクをはったページにもやりかたがありますが、GCP web console の Logs-based Metrics 機能に飛ぶと、あたらしく metrics を作成することができます。
ここで、上記に例示しました log 出力に対して metrics を作成してみましょう。
今回は、単位時間ごとの各 API の呼び出し回数 (log に現れた回数) を metric にしようと思いますので、Metric Type は Counter としておきます。(もう片方の type は Distribution ですが、そちらには今回は触れません)
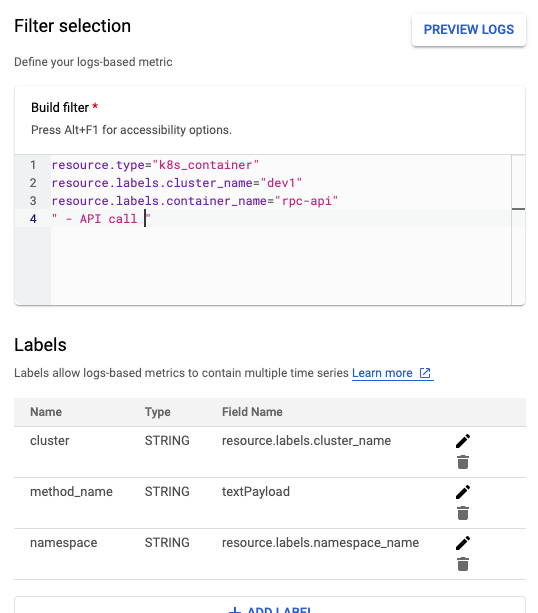
Filter 条件です。今回は GKE container から log を出しているので、その cluster と container name で filter しています。 また、上記した例の log 行を抽出するためにキーワード " - API call " も指定しています。これで必要な log のみが取得できるようになりました。
また、Labels のところには metric に付与する label を指定しています。こうしておくことで、label ごとに集計を変えたり特定のものに絞って確認することができるようになります。
今回のポイントは、“method_name” と名付けた label です。この定義は以下の画像のようになっています。
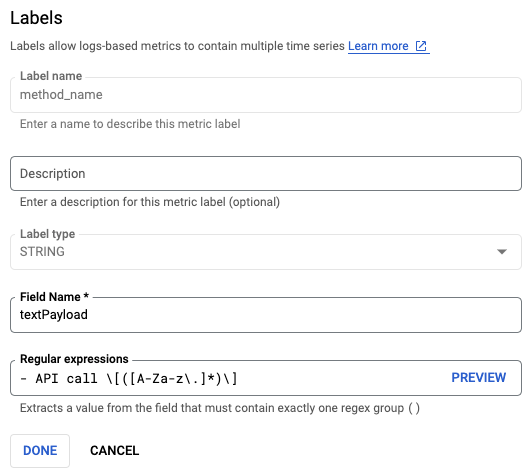
log から抜き出す文字列を正規表現で指定しています。今回は log の形式より、- API call \[([A-Za-z\.]*)\] という正規表現で [ ] の中の文字列を抽出するようにしています。これで、各 metric data に label として API 名をつけることができます。設定方法の詳細は こちらの document にあります。
API 名が数十種類以上になるなどのときは事前に filter しておくなどしたほうが仕上がりが見やすくなるかもしれません。このあたりは試行錯誤しながら調整ですね。
うまくいくかな…?
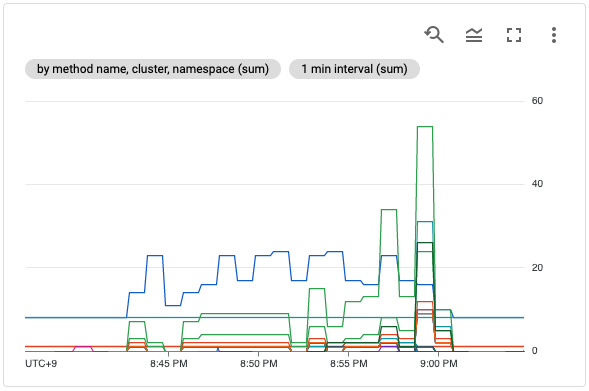
作成した metric を使って、Monitoring dashboard に chart を追加してみました。いつもながらサンプルが少ないのでぱっとしない見た目ですが… よい感じで時系列に呼び出し回数が可視化されています。まっすぐな横線で呼び出し回数が一定にずっと続いているのは、healthcheck に使われている API でしょう。
metrics がうまく見つからないときは、Metrics explorer で探してみましょう。Logs-based Metric という category もあるので、metrics さえ入っていれば探すのにそこまで苦労は無いかと思います。
費用は?
大量の log に対してこういった処理を行うことになるので、Logs-based Metrics には専用の費用がかかるかな…? と調べたのですが、特にそのような情報は確認できませんでした。もちろん、log そのものの量や metrics の量に対しては費用がかかりますので、いつもどおり条件・内容を確認して計画的にご利用ください。
Operations Suite > Pricing > Cloud Logging > Logs-based Metrics
まとめ
アプリケーションに手を入れること無く、log にある情報からシステム稼働状況の可視化を進めることができました。
今回は触れませんでしたが、count ではなく distribution の metric type を使うと、log に出力されている API 呼び出しにかかった時間の分散を可視化したりできそうです。これを使えば、trace を仕込むこともなく時間がかかっている処理の特定ができるかもしれませんね。機会があれば試してみたいと思います。
