
シリーズ・すこしずつがんばる streaming data 処理

パブリッククラウドでよくマネージドで提供されているサービスのうち、活用が大きなアドバンテージになると感じるものに、リアルタイムの逐次データ処理、streaming data 処理があります。これを実現するために、OSS はじめ多くのベンダーからもさまざまなものが提供されていますが、GCP で streaming data 処理といえばやっぱり Dataflow です。(独断と偏見)
Streaming data 処理とは
単に streaming data 処理というとさまざまな単位や仕組みのものがありますが、ここではネットワーク等の IO から流れてくるデータを集めて逐次処理するようなものを扱うこととします。
具体的な例
たとえば、こういった機能が効率的に実装できます。
- エンドユーザーのログインイベントを集めてリアルタイムでアクティブユーザー数を計算する
- CPU 使用率などのモニタリング指標を集めて 5 分間隔の平均をグラフ化する
- 一日に一度、データベースのデータを集計する
最後のものは通常、どちらかというとバッチ処理と呼ばれるものですが、Dataflow (等) を使うと、こういったバッチ処理を効率的に実装することもできます。
「いつくるかわからないデータを待ち受け、それをある程度の単位でまとめて、データの内容によって複数の処理をし、別のデータベースなどに保存するといった処理」は、ゼロから実装しようと思うとなかなかめんどうなものです。テストもとてもめんどうです。それが streaming data 処理フレームワークを使うことで、データ処理部分の実装に集中することができるようになります。
Dataflow とは
GCP で提供されているフルマネージドのデータ処理サービスです。
https://cloud.google.com/dataflow
Apache Beam という OSS があり、これを利用して処理を実装することで、抽象化したデータを共通のパイプラインで処理できます。(というか Beam はもともと、Dataflow の framework を OSS 化したのがはじまりだったとか 1)
Beam が support する IO、つまり入出力の種類は こちら にリストがあります。
これらを input、output として間にいろんな処理を組み込むことができます。
ただ Beam を使った実装が独特で、触れる機会が多いコマンド形式のプログラムや REST API 実装などともかなり違っていて、streaming data 処理のコンセプトとあいまって最初の敷居が高く、自由に実装できるようになるまでにはある程度の慣れが必要という感覚があります。
しかし…?
様々な入出力に対して柔軟に処理を追加できる Dataflow (Beam) は、以前は独自性が強い強力な機能でした。しかし昨今、GCP だけで見ても以下のような様々な機能が追加され、Dataflow を使うことなく高度な機能を簡単に利用できるようになってきています。
- Cloud Logging - Sink 経由での他 storage への送信
- Cloud Run Jobs
- Batch (GCP)
- Pub/Sub から Big Query への直接投入 (BigQuery subscriptions)
- Pub/Sub から Cloud Run など web service への送信
- Cloud Spanner change streams (これは今のところ Dataflow 推奨…?)
- Cloud DataProc の DStreams や Structured Streaming
また、Dataflow というと ETL (extract, transform and load) ですが、ELT (extract, load and transform) で済んだりむしろそのほうが効率がいいようなケースもあり、適材適所での選択が重要だなあと思わされます。
ここからのステップ
この記事は “シリーズ” としていますが、以下のように進めていきたいと思っています。 ひとつひとつは情報を最小限にして情報の見渡しをよく、パッと試せるような内容になるようまとめてみます。
- Dataflow template を使ってみる → この記事後半
- いちばんかんたんな pipeline を実装してみる → つづき (2)
- streaming で逐次処理をやってみる → つづき (3)
- Spark 等、他のものも試してみる…? → つづき (4)
Dataflow template を使ってみる
ということでさっそく、実際に Dataflow で処理を実行することを体験してみましょう。
GCP project と account、権限などが必要ですが、長くなるのでここでは触れません。権限についてよくわからない場合や、実行しようとしてエラーが出た場合などは管理者に聞いてみてください 🙏
また、記事の範囲ではたいした料金はかかりませんが、内容を改変したり何度も実施したりする場合はデータ量等によって費用にご注意ください。大量のデータを input として使用したり、繰り返しの実行や長く処理を続けたりすると高額になる可能性があります。
Dataflow template とは
Dataflow を使ってみるのにいちばんかんたんなのは、template を使ってみることです。Dataflow ではよく使われる処理のモデルをいくつか用意してくれているので、これらの中から用途に合わせて選択し、パラメーターを与えてやるだけでコードを一切書かずに処理を実現することもできてしまいます。
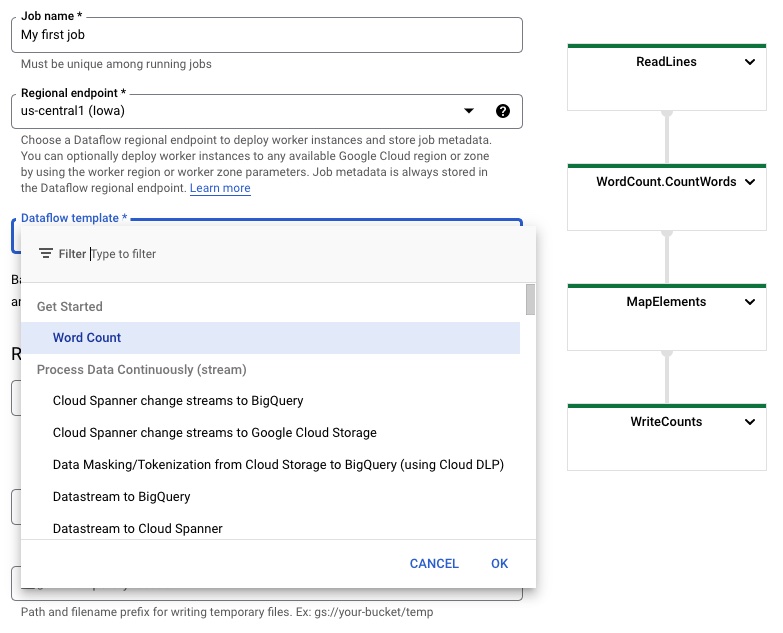
選択肢には Word Count のようなデモっぽいものから、Pub/Sub Topic to BigQuery、GCS to Elastcsearch のような日頃のちょっとした運用作業などにちょうど便利そうな実用的なものまで、かなり多く揃っています。
昔々はたしか template が用意されておらず、何かするにはとにかくまずコードを書くとこからという敷居が高い製品だったように記憶していますが、これならはじめての人でも手がつけやすそうです。
また、すべての template かは確認できていませんが、source も公開されている ようなので、やりたいことがほとんどおなじだけどちょっと違ってて惜しい…!といったときや、単純にサンプルとしても使えるようになっています。
やってみよう
では、template をひとつ実行してみましょう。
今回はお手軽に、GCP の Web Console から実施してみます。Dataflow Jobs のページから、“CREATE JOB FROM TEMPLATE” というメニュー (ボタン?) を選択します。
job 作成の設定は、以下のようにしてみました。
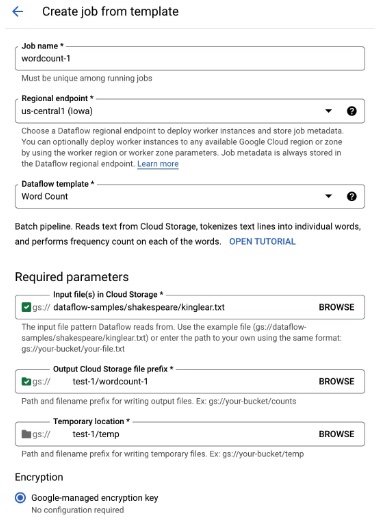
output、temporary 用の GCS bucket は、お試し用のものを作成してそれを指定してください。
input file は dataflow-samples という GCS bucket で公開されているもの (gs://dataflow-samples/shakespeare/kinglear.txt) を指定しました。じぶんで用意したものを使用する場合は、お試し用で作成した GCS bucket 下に text file を置き、それを指定してあげるとよいでしょう。
これで実行すると、以下のように pipeline が表示されます。
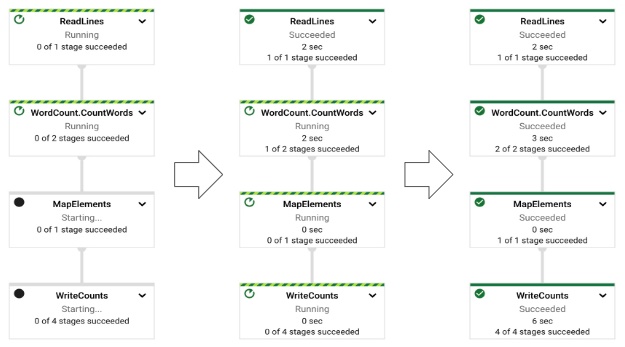
最初は左端のように実行中や待ち状態のステップがありますが、徐々に右のように進行して最後まで完了すると右端の状態になり、job が完了状態になります。非常に視覚的でわかりやすいですね。
指定した GCS の path を確認すると、text file が生成され、中に単語とあらわれた回数のデータが保存されているはずです。
❯ gsutil cp gs://xxxxtest-1/wordcount-1/-00000-of-00001 /tmp/
Copying gs://xxxxtest-1/wordcount-1/-00000-of-00001...
- [1 files][ 47.8 KiB/ 47.8 KiB]
Operation completed over 1 objects/47.8 KiB.
❯ head /tmp/-00000-of-00001
feature: 1
block: 1
Cried: 1
scatter'd: 1
she: 44
sudden: 1
silly: 1
More: 6
'twill: 2
out: 68
うまくいっているようですね。
まとめ
Streaming data 処理についての概要から、Dataflow template のお試しまでをやってみました。
お試しの内容はサンプルそのままでしたが、なんとなく雰囲気は感じられたように思います。template には Big Query などその他おなじみのサービスを使うものがたくさんあり、用途に合えば便利に使えそうです。
次回からは、より具体的な要件にあわせたカスタムの処理を実装してみたいと思います。
参考
-
About Apache Beam Project ↩︎
