
スクウェア・エニックスの"とあるシステム"のSite Reliability Engineering

はじめに
こんにちは、情報システム部 SRE 橋本です。
普段はクラウドエンジニア(SRE)としてチームリードをしています。興味関心がインフラ、Observability、SRE、Security、Golangといった分野であり、 Japan Google Cloud Usergroup for Enterprise(Jagu’e’r ジャガーと読みます)でObservability/SRE分科会のオーナーを担当させていただいております。その縁もあって先日Innovators Hive at Cloud Next 2022でコミュニティ運営についてお話をさせていただきました。
この記事では現在チームリードをしていてビルドアップ中でもあるSREチームについて考えていることをお話したいと思います。 また、このSREチームについてのインタビュー記事も掲載いたしました。メンバーやチームの雰囲気を伝えたいと思って作っておりますので、よろしければご覧ください。
本記事は以前Jagu’e’r分科会で発表した資料を交えてお話をします。内容はシステムやSREとしてやることというよりも、チームや組織についての現在での考え方に重きをおいて書いています。
我々のSREチームについて
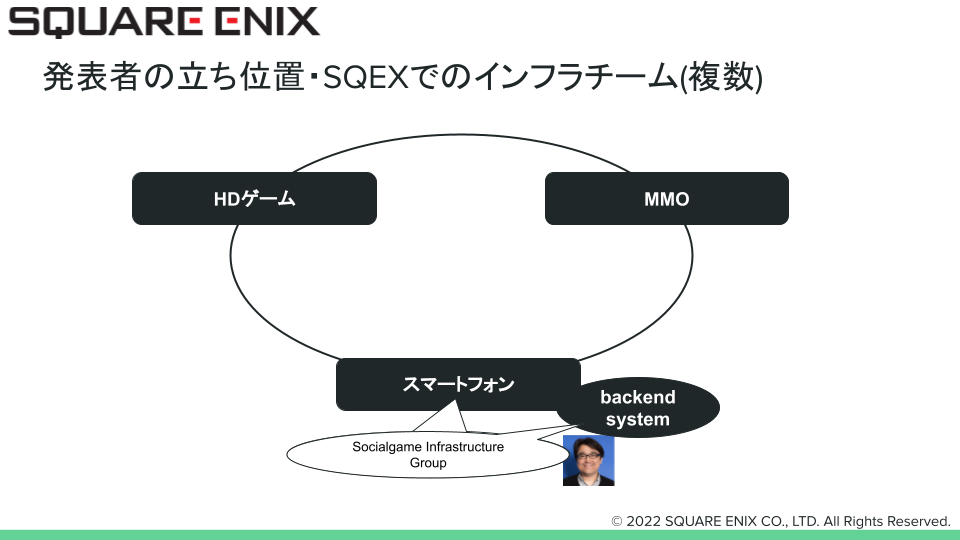
タイトルに”とあるシステム”とつけているのは、当社ではゲームやシステムによっていくつかのインフラチームが存在しており、その一部のチームやシステムであることを意味しています。あくまで一部でのSREに関することを書いており、スクエニ全体での取り組みではない点をご承知おきください。我々は下の図で吹き出しがついているスマートフォン系のバックエンドシステムを担当するチームになります。
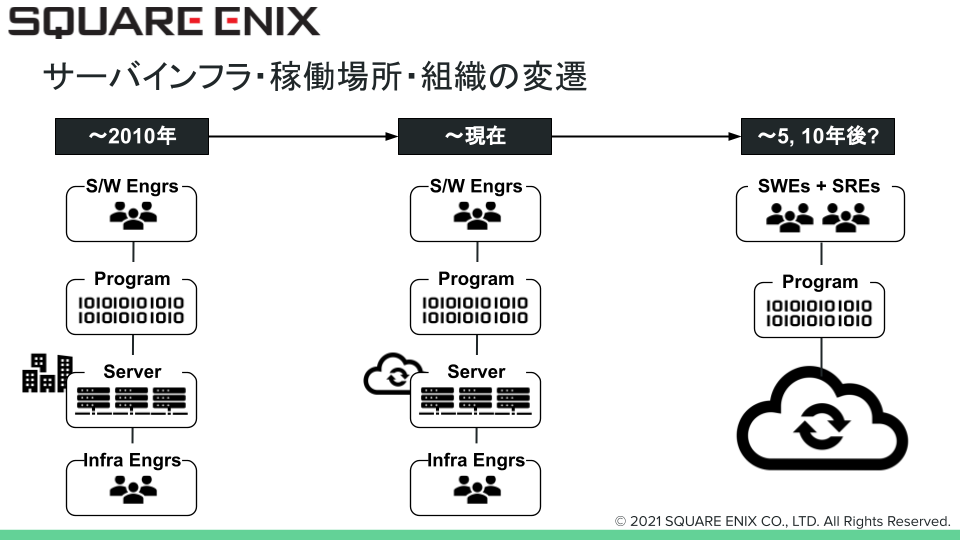
システムと組織の変遷・クラウドネイティブ化との関わり
システムと開発チーム・インフラチームの関係性
下図はシステムとそれを取り巻く組織の遷移を簡単な図にしたものです。一番左側の列ですが自社のデータセンタ(DC)でインフラエンジニア(図のInfra Engrs)がサーバ等のインフラを構築し、開発エンジニア(図のS/W Engrs)がプログラムをデプロイしてサービスを提供している様子を図式化したものです。ビルが立ち並んだアイコンはDCをイメージして貼り付けています。
真ん中の列はDCがクラウド(雲の形のアイコン)に変わっています。2010年代からさまざまなクラウドが誕生し当社でも活用されてきました。ただ、サーバが稼働する場所は変わるものの組織としての形は大きく変わりませんでした。物理的なサーバが仮想マシン(VM)になったり、ラッキングや障害ディスクの交換など物理的な作業がWebGUIやAPI実行、コマンド操作等に置き換わるなどしたものの、サーバを構築し維持運用するインフラチームとプログラムを開発・メンテナンスする開発チームという図式は大きく変わることがなかったと思います。
そして、一番右側の列です。「〜5、10年後?」と表現していますが、クラウド化が進むにつれてエンジニアの組織体制も変わるであろうことを図式化したものです。
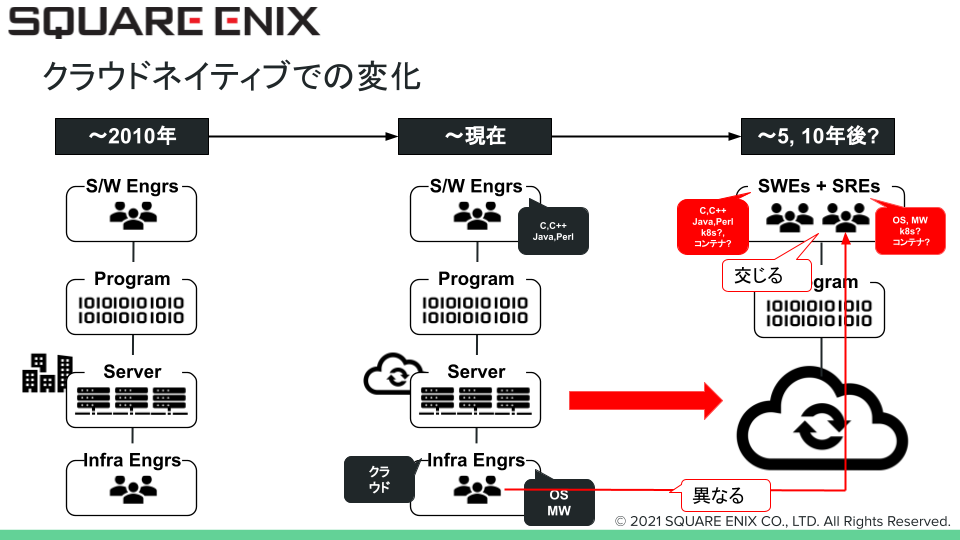
クラウドネイティブによって感じる変化
システムがよりクラウドに適したものに変わることをクラウドネイティブの一つの意味だと考えていますが、それによって組織の形態も自ずと変化するであろうということを図で示しています。これまでサーバを中心にインフラが構築されてきましたが、今後はPaaSの活用やKubernetesのようにマニフェストを元に開発エンジニアが比較的容易にワークロードをデプロイすることが出来るコンテナ実行環境が一般化することで、「インフラエンジニアがサーバを作り、それを開発エンジニアに引き渡す」という形態が少なくなってくるであろうと想像しています。
例えばKubernetesでシステムを構築すると、しばしば開発エンジニアとインフラエンジニアの組織で何をどこまで管理するのか明確に線引することが難しいと感じることがあります。「クラスタはインフラエンジニアが見ると良かろう。ではマニフェストは?コンテナイメージは?」などと悩んだ経験は皆さんもあるのではないでしょうか(図での”交じる”の部分)。
またインフラエンジニアにとっては、開発エンジニアに近い立ち位置でシステムに関わるようになったり、VMなどよりもより抽象化されたシステムを扱うようになることで異なるスキルセットが必要となる場面が増えてくるのではないかと考えています(図での”異なる”の部分)。
そのような変化から自然と開発・インフラエンジニアという別のチームではなくソフトウェアエンジニア(図では SoftWare EngineerSとしてSWEsと記載)、インフラ寄りに詳しくサイト信頼性を担保するエンジニア(図ではSite Reliability EngineerSとしてSREsと記載)がより近いところで一緒に活動するようになるであろうと考えています。
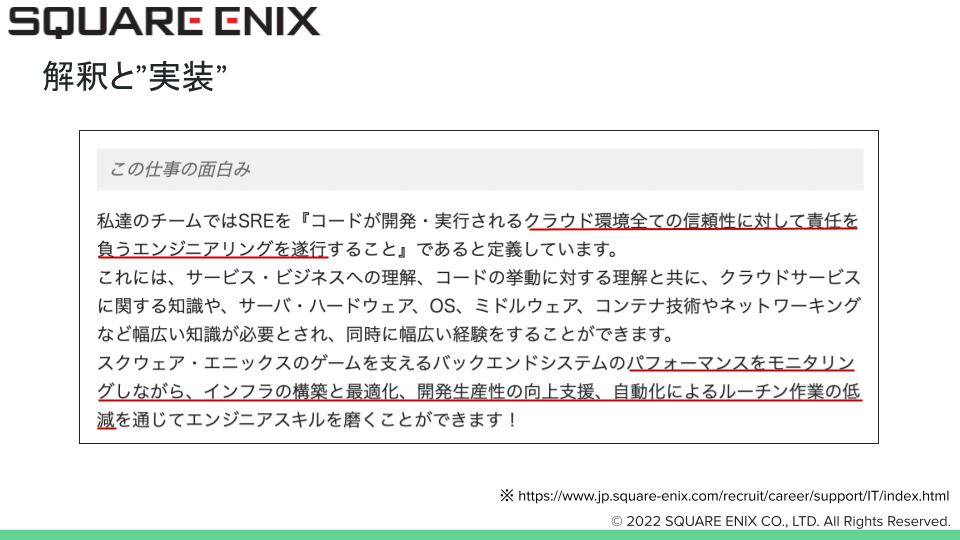
目指すクラウドエンジニア(SRE)の定義と仕事
いままで記載した考えはあくまで筆者の私見ではありますが、この考えに基づいて記述したSREの募集要項を一部抜粋したものになります。非常に風呂敷を広げた内容でまだまだこれを目指している途上ですが、これを目指して現在チームを作っている状況です。
クラウドエンジニア(SRE)の価値提供
ステークホルダと提供する価値の整理
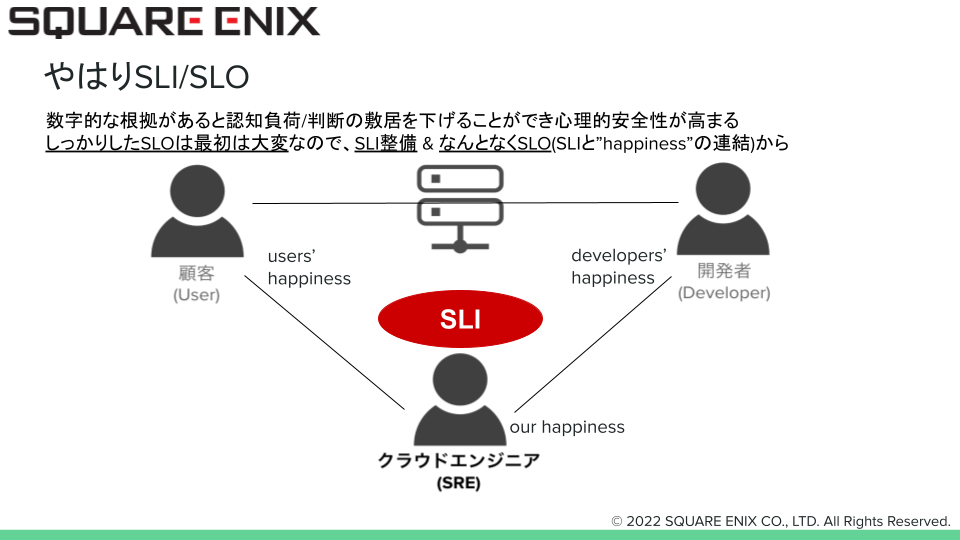
先の募集要項の抜粋では文章でSREが遂行することの定義を記載しましたが、図式化したものが以下の図になります。 SREにとっては左からエンドユーザ様(User)、サービスインフラ(図のサーバのアイコン)、開発者(Developer)がそれぞれ価値提供先であり、図のような提供価値であると整理しています。
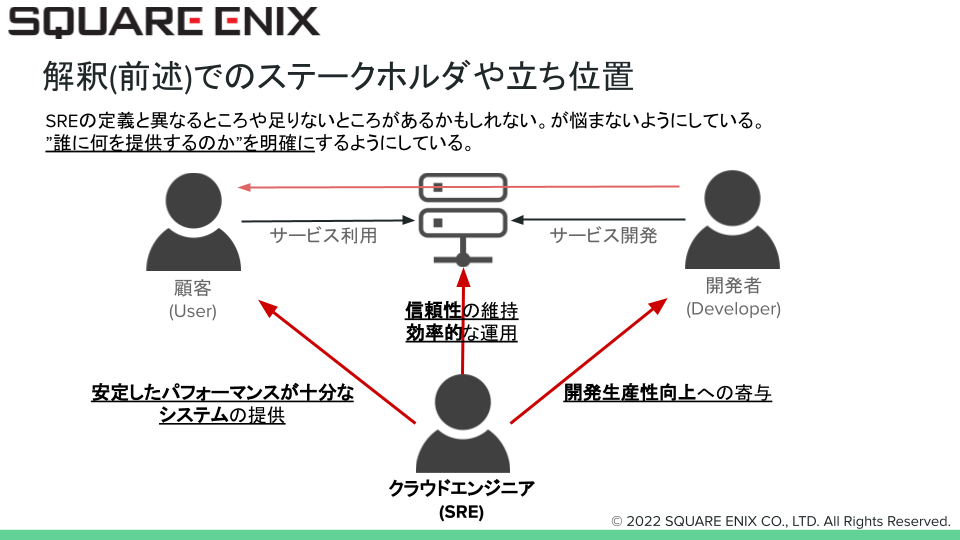
提供価値がいっぱいある!
簡略化すれば先の図の通りではあるのですが、実際の業務となると沢山あります。一例として以下の図になりますが表現しきれないものが沢山あります。
顧客の満足(users’ happiness)や開発者の満足(develpers’ happiness)を追い求めるべくやるべきことがいっぱいありつつも、自らの業務の足場を固めるために自動化やトイルの撲滅もしたい、SLI/SLOの定義もしたい…などとやるべきこと、やりたいことが溢れて何から手をつけるべきか分からなくなったという経験はないでしょうか。わたしはそのような状態に陥った経験があります。
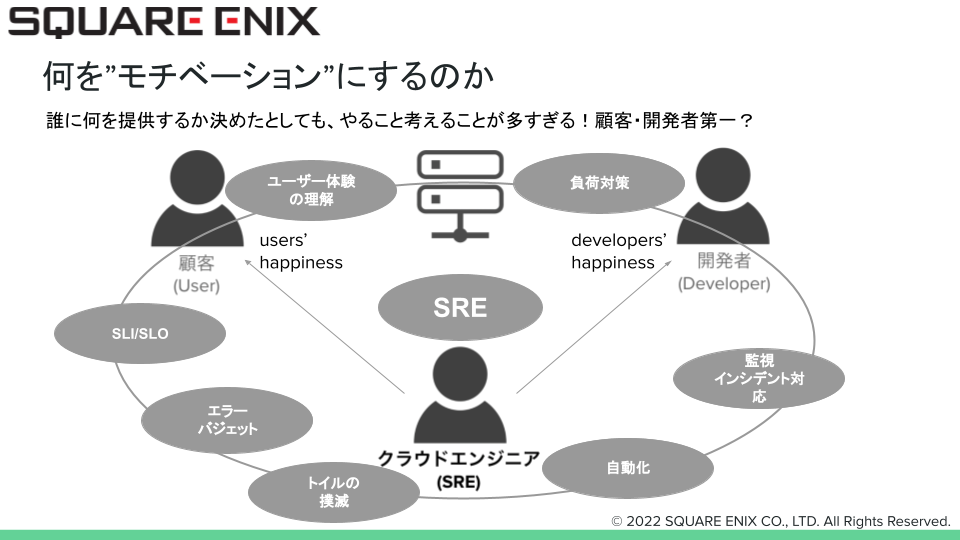
まずはできるところから・続けられることから
様々なことを遂行するにしても自分たちがパフォーマンスを出し続けれなければ、結果的に顧客や開発者への価値提供もままならないと考えています。まずは自分たちの満足度があがる・モチベーションが保てるものから手を付けていくと良いのではないか、ということで、少しネガティブな聞こえがあるかもしれませんが”自己中心的”と下図では表現しました。
もちろん、システムの運用維持や顧客・開発者へ果たすべきことをゼロにするわけでなく、意識的に新しい取り組みを行う際の優先度の中で自身にとって大事なことを優先してみる、調整・交渉を試みる、ということになります。なかなか自分たちのチームのメリットを優先する目標を立てづらいという苦い経験もあったので、同じ悩みの方の気付きになると幸いです。
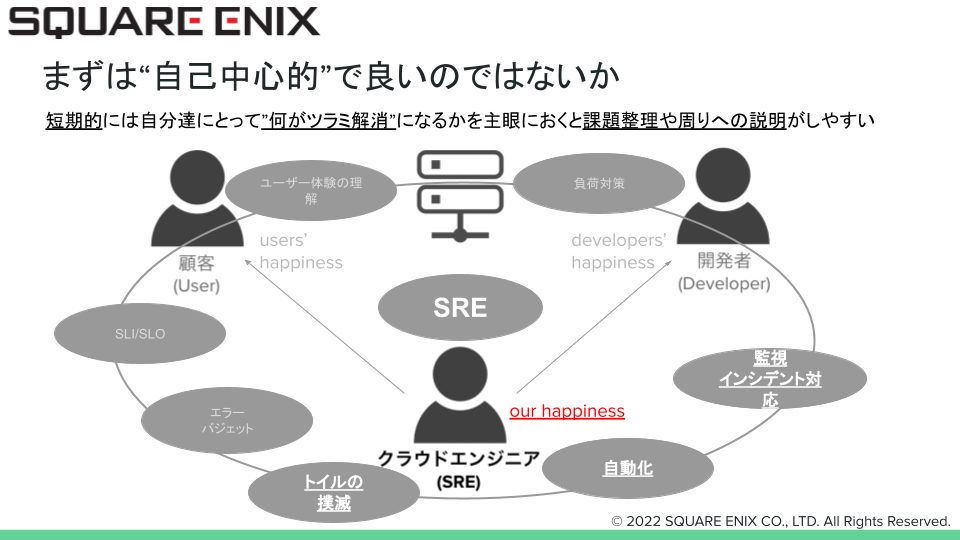
最後はみんな嬉しい状態を目指したい
ステークホルダが嬉しい状態
いつまでも自らの組織・チームだけに良い状態を維持するだけでは、多くの組織では本来のSREチーム・インフラチームとしての期待値を達成できないと思います。ですので、あくまで短期的には”自己中心的”であり、足場が固まったら顧客・開発者の満足度を上げるために何をすべきかを考えていくことが重要だと考えています。
この満足度(happiness)とはなにか。下図の”?”の部分が何か?という点で出てくるのが次の項目になります。
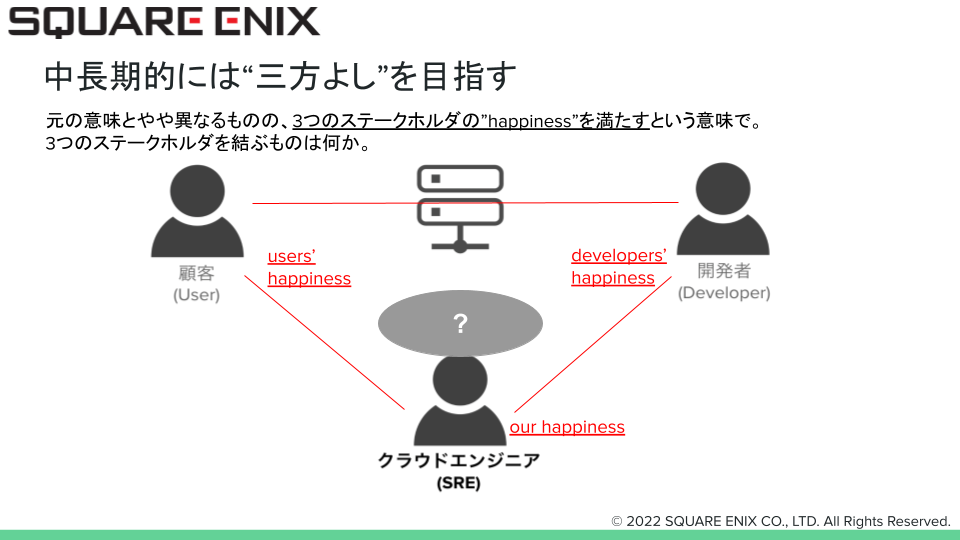
“みんな嬉しい”を繋ぐものは?
ここで下図のようにSLI/SLOが出てきます。絵ではSLIとしか書いていません。経験的にではありますが、SLOをいきなり決めるのは難しいケースが多いでのはないかと思っており、SLOは一旦脇において、まずはSLIを整備することが大事なことではないかと考えています。
SLOどうすればいいの?となったときは
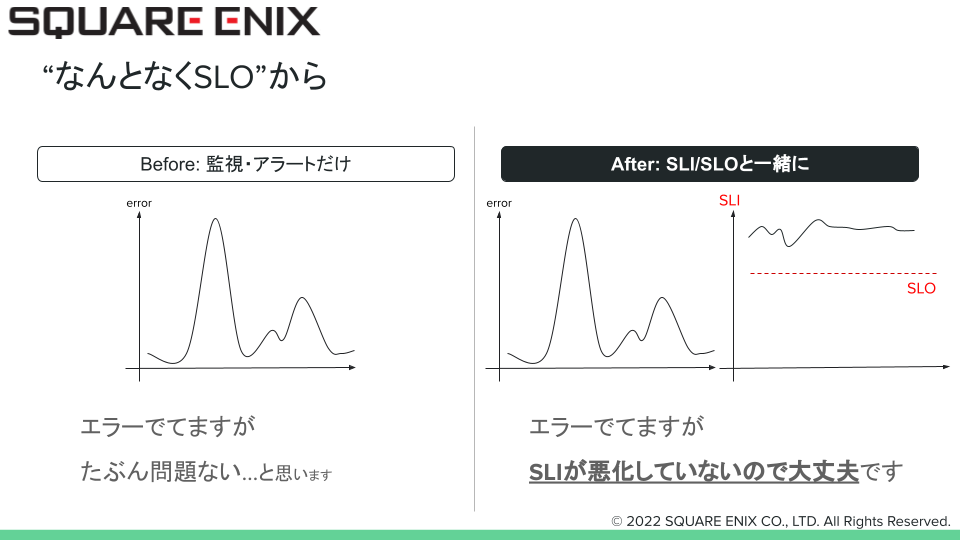
SLIが整備されてくると、エラーやアラート、もしくは障害が発生した場合にビジネスサイドや開発者の人たちと会話をする際に”なんとなくSLO”をもとに会話をするのが取っ掛かりとして始めやすいと思っています。経験的に大丈夫そうなのか大丈夫じゃなさそうなのかという感覚とSLIで明確になっている数字/グラフをリンクさせて会話するだけでもSLOですし、立派なSREだと考えています。
自身の苦い経験からの話になりますが、下図の左側のようにモニタリングのグラフ/SLIだけだとエラーが出たこと自体を問題にしてしまい、実際は誰の不幸にもなっていない事象に対してインフラエンジニアが疲弊してしまったり、何も根拠なく問題ないという憶測を述べてしまうバツの悪い思いをすることがありました。
反対にSLIとSLOを一緒に、”なんとなく”でも良いのでしきい値のラインを決めて問題なのかどうかをビジネス/開発サイドと小さな範囲でも会話を始めることがSREの第一歩になると思います。
少し余談ですが、SLIを作り始めるととても多くなることがあります。User JourneyをもとにAPIごとにSLIダッシュボードを作っていくと数十個、百数十個のグラフがある…という状態に陥りそうになります。そこはぐっと堪えて、重要なAPIを中心にCritical User Journeyを選択することが大切です。(沢山のSLIに溺れてしまいます)
最後に
SREを始めてみたいが何をすればいいか分からない、はじめてみたが何から手をつければいいか分からないという方は多いのではないかと思います。本記事では以下のまとめの内容をお話させていただきました。わたし自身も悩んできたことを、こうすると良いのではないかと試行錯誤をしながら今も実践中の内容であり答えがはっきりしていないものもあります。それでも、同じ悩みを抱えている方々の参考になるととても嬉しいです。最後まで読んでいただいてありがとうございました。
