
AWS上でログを収集[S3]→加工[Glue]→閲覧[Athena]してみた!
この記事はAWS for Games Advent Calendar 2022の25日目の記事です。
皆さんはログの扱いに慣れておりますでしょうか?
必要なログは全て綺麗に ETL していつでもばっちり見れる状態です! となっていればどんなに良いことか、、中々後回しにされがちな部分かと思います。弊社でも様々なゲームが平行稼働している中、
- 大量のログがローテートされてサーバから消えていく
- タイトル別でうまくいい感じに一か所で管理したい
- 何かインシデントが起きた時、急いでいる時にサーバに SSH してログを漁りたくない
- さっと見れるようにしたい
みたいな話がありつつも、中々手を付けられずにいました(主に syslog 周り)。今回 AWS さんの協力もあり、技術取得の一環で検証をスタートしてみました。「ログを S3 に集めて、 Glue でなんやかんや加工してみて、 Athena でいい感じに閲覧してみたい。」 みたいなことを考えている人には刺さるかもしれない内容となっています。
本題
今回、収集対象としたログは
「 audit 」「 messages 」「 secure 」「 nginx ( access , error ) 」
の4つです。ゲームログも集めてみたいな~と思いつつ、まずは検証としてわかりやすい syslog 周りからやってみました。
※ただし、後半のログの加工は audit ログのみとなっております。(すべてを検証しきれず。。) ご了承頂ければと思います。
全体フロー
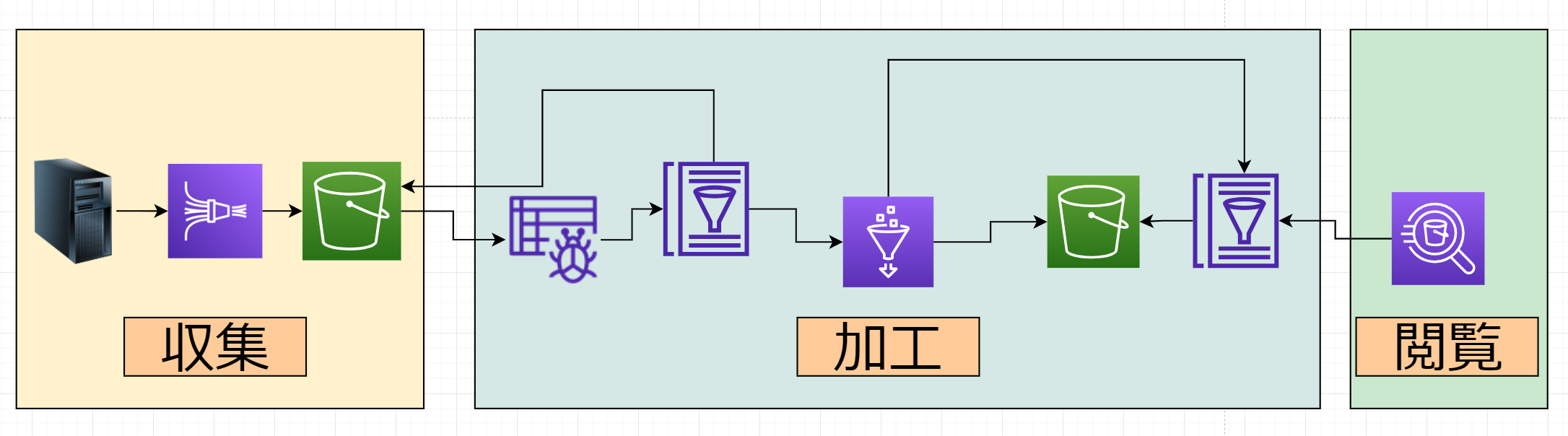
早速ですが、結論から。最終的には(現時点で)以下のような構成になりました。
順を追って説明します。
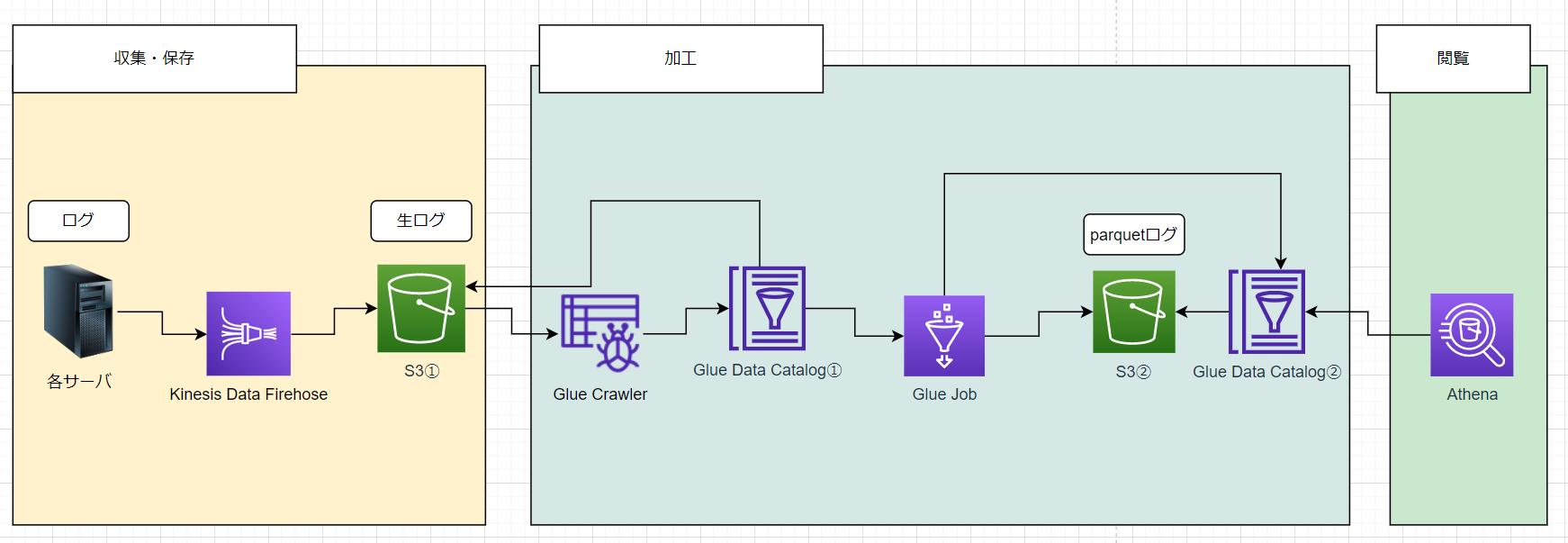
収集
まずは各サーバからログを集めて S3 バケットに格納するまでの部分です。
図でいうと、以下の部分となります。
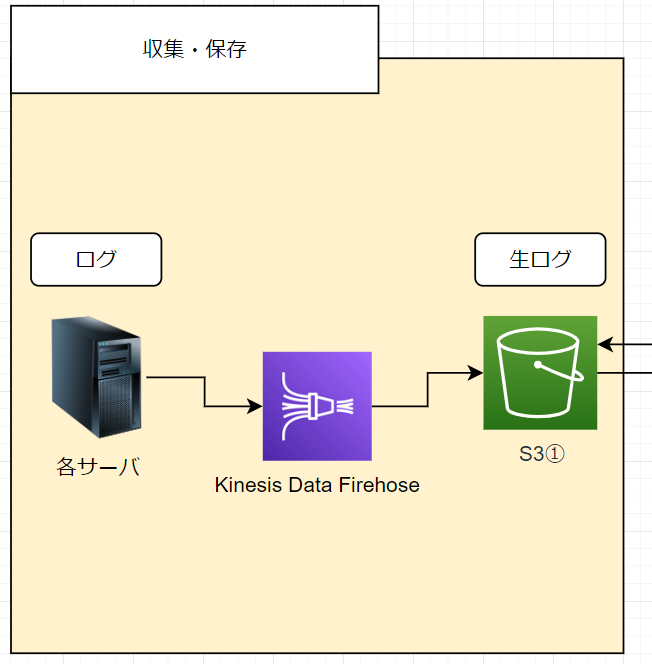
ここではあまり難しいことはしておらず、
各サーバ→ Fluentd → Kinesis Data Firehose → S3① へ格納
のようにしており、とにかくログをできるだけ加工せずに S3 へ送り出しているだけです。
できるだけ加工せず
というのは少し重要なポイントで、今回は加工する場所はなるべく1箇所(=つまり今回でいう Glue )にしたいという思いがありました。理由として、下記が挙げられます。
- ログの保全という観点から S3① には生ログをそのまま保存したい
- 加工する場所を増やしてしまうと複雑性が増してしまう(どこで何をしているか分かりづらくなってしまう)
S3 へログを格納する際に、どのサーバからのログかを判別するために Fluentd 側でログに hostname を追加する場合があるので、ここではできるだけという表現を使っています。
Fluentdでのログ収集
今回は、各サーバ~ Kinesis Data Firehose までのログ収集を Fluentd を使っています。
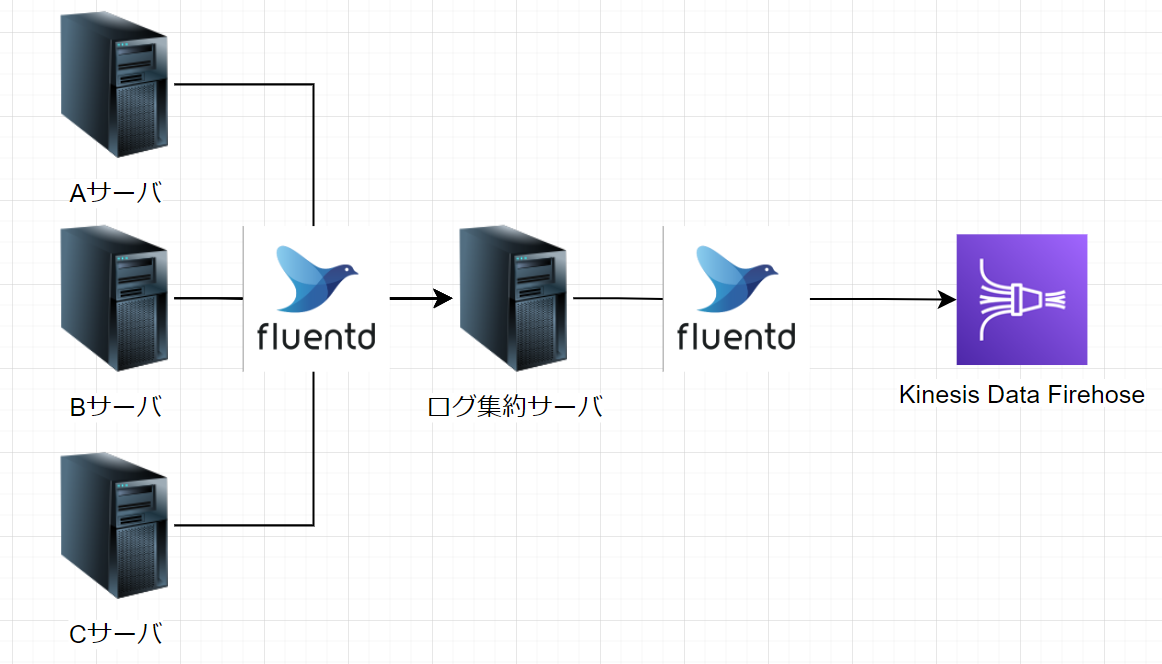
- 各サーバからログ集約サーバ
- ログ集約サーバから Kinesis Data Firehose へ
上記2箇所にて、 Fluentd を利用しています。ログを一度集約サーバに集め一次保存することで、ログの欠損をカバーできたり
、Kinesis Data Firehose に向けて一定の粒度で送れたり、管理がしやすくなります。一方で、ログ集約サーバの冗長性を考えたり、サーバ台数によって負荷の増減を考えたりすると各サーバから kinesis Data Firehose へ送るという選択も全然ありだと思います。実運用を通じて負荷面を考えたりする必要が出てきた場合は、構成が変わってくる箇所かなと考えています。またFluentd の設定は特に変なことをしておらず、 fluent-plugin-kinesis-firehose を使って転送しているだけとなります。
参考: fluent-plugin-kinesis-firehoseでAmazon Kinesis Data Firehoseにログを転送する
Kinesis Data Firehose の設定
一箇所だけ、後程 Glue で加工しやすいように S3 への格納時の prefix だけ指定してあげています。
S3 バケットプレフィックス
audit/!{timestamp:'year='yyyy'/month='MM'/day='dd'/hour='HH}/
上記を指定してあげると、以下のようになります。
バケット名/ログ名/year=2022/month=12/day=25/hour=12/
S3① へのログの収集はこんな形となります。後は S3 ライフサイクルなどを利用して、ログの保存期間の調整などをしていくことになりそうです。
加工
ここまでで、生ログを S3 バケットに格納するところまで記載しましたが、ほんとの本題(時間がかかったところ)は加工の部分でした。というのも、Glue をまともに使ったことがなく、未だに全く扱いきれていないのです。日本語の記事もあまりなく、なかなか手探りではあったのでもっと効率よく出来たんじゃないかな~と日々感じています。弱音はこれくらいにして、続いてはこちらとなります。
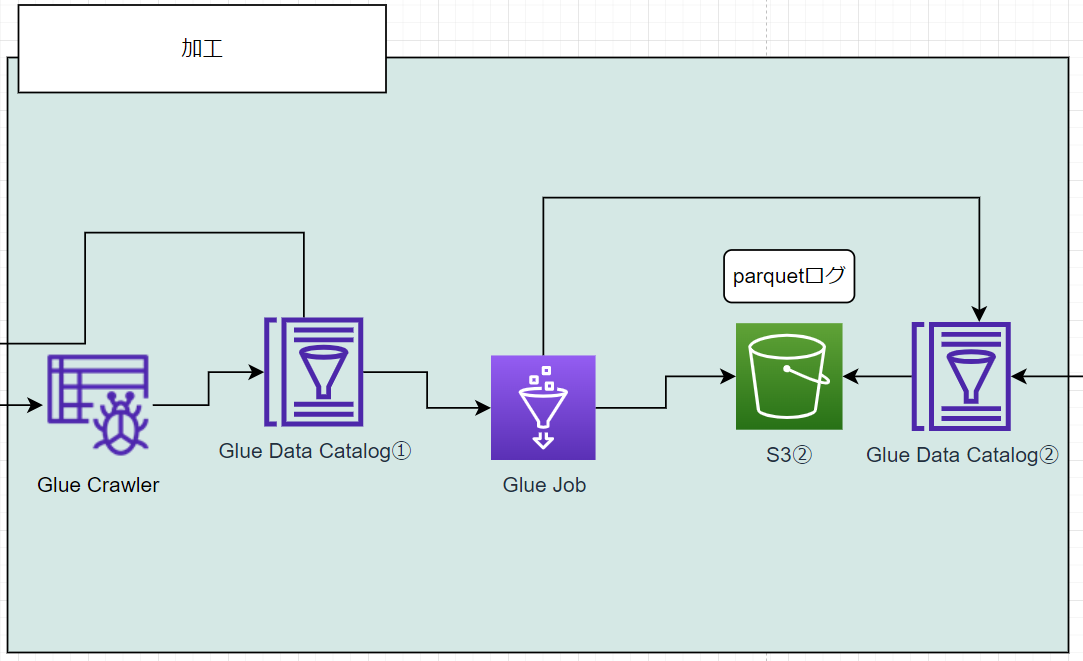
加工フローとしては、以下のようになり
Glue crawler → Glue データカタログ→ Glue job → S3② ( parquet 形式のログデータ)
簡単に説明すると、
- S3① のデータをクロール(総なめ)してデータカタログに登録
- Glue job でごにょごにょして閲覧可能な状態に加工して S3② へ格納
のようになります。恐らくデータカタログとは??となると思いますので、ここだけ引用しておきます。
AWS Glue data catalog は Apache Hive メタストア互換で、データベースや、テーブル、パーティションに関する情報(メタデータ)を S3 に保存します。 この時点ではあくまでこのデータはどこにあるか?などの情報だけを持っているだけで、データを変換して保存し直しているわけではありません。ただ data catalog にまとめることによって複数の箇所にあったデータを Athena を利用して一括で検索出来るようになったり、後述の Job や EMR などで Glue data catalog を参照して、変換・集計することが出来るようになります。
上記含め、 Glue 関連の単語はここに纏まっていたのでオススメです。では今回、どのように Glue 周りを利用したかというと、audit ログを Glue で加工してみました。audit ログは様々な情報が書かれていますが、“何かあった時"に必要な情報のみに絞るために加工していきたいと思います。
参考:AWS Glue を使って S3 →データ加工→ S3 をやってみた
DB 作成~クローラの作成
まずは 1. S3① のデータをクロール(総なめ)してデータカタログに登録 こちらの設定を進めます。
始めに、S3① にある audit ログを Glue 側から読めるようにデータベース①を作成します。(図のデータカタログ①に該当する部分)
# DB 定義
[cloudshell-user@XXXXXXXX ~]$ cat << EOS > database-definition.json
> {
> "Name": "syslog",
> "Description": "analyze syslogs."
> }
> EOS
# DB 作成
[cloudshell-user@XXXXXXXX ~]$ aws glue create-database --database-input file://database-definition.json
#確認
[cloudshell-user@XXXXXXXX ~]$ aws glue get-database --name syslog
一点注意事項として、データベースの名前にはアンダースコア( _ )を使えないことです。アンダースコアを使ってしまうと上記の CLI では問題なく実行できますが、後々Athena で閲覧する際にエラーとなってしまいます。
参考:[ AWS Glue ]データカタログのテーブル名にハイフンが含まれていると特定コマンドの対象にできない
続いて、クローラを作成していきます。
※カスタムパターン定義について、今回は下記のような audit ログを収集することを前提に作成しています。
type=USER_START msg=audit(1671084070.007:86314): pid=6148 uid=0 auid=1000 ses=12082 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=PAM:session_open grantors=pam_selinux,pam_loginuid,pam_selinux,pam_namespace,pam_keyinit,pam_keyinit,pam_limits,pam_systemd,pam_unix,pam_lastlog acct="centos" exe="/usr/sbin/sshd" hostname=xxx.xxx.xxx.xxx addr=xxx.xxx.xxx.xxx terminal=ssh res=success'
#カスタムパターン定義の作成
#カラム名は分かれば何でもOK
[cloudshell-user@XXXXXXXX ~]$ cat << EOS > classifier-grok.json
> {
> "Classification": "custom-log",
> "Name": "audit-classifier",
> "GrokPattern": "^%{DATA:type} %{DATA:msg} %{DATA:pid} %{DATA:uid} %{DATA:auid} %{DATA:ses} %{DATA: subj} %{DATA:msg2}$"
> }
> EOS
#作成
[cloudshell-user@XXXXXXXX ~]$ aws glue create-classifier --grok-classifier file://classifier-grok.json
#確認
[cloudshell-user@XXXXXXXX ~]$ aws glue get-classifier --name audit-classifier
# crawler の作成
[cloudshell-user@XXXXXXXX ~]$ CRAWLER_ROLE=AWSGlueServiceRole
[cloudshell-user@XXXXXXXX ~]$ DATABASE_NAME=syslog
[cloudshell-user@XXXXXXXX ~]$ CLASSIFIER=audit-classifier
[cloudshell-user@XXXXXXXX ~]$ S3_BUCKET_NAME='バケット名'
[cloudshell-user@XXXXXXXX ~]$ cat << EOS > audit.json
> {
> "S3Targets": [
> {
> "Path": "s3://${S3_BUCKET_NAME}/audit",
> "Exclusions": []
> }
> ],
> "JdbcTargets": [],
> "DynamoDBTargets": [],
> "CatalogTargets": []
> }
> EOS
# crawler の作成
[cloudshell-user@XXXXXXXX ~]$ aws glue create-crawler --name audit-crawler --role $CRAWLER_ROLE --database-name $DATABASE_NAME --description "convert audit" --classifiers $CLASSIFIER --targets file://audit.json --tags Name=audit,Creation=cli
#確認
[cloudshell-user@XXXXXXXX ~]$ aws glue list-crawlers --query "CrawlerNames[?contains(@, 'audit')]"
[cloudshell-user@XXXXXXXX ~]$ aws glue get-crawler --name audit-crawler --query "Crawler.{NAME: Name, STATE: State, TIME: CrawlElapsedTime}"
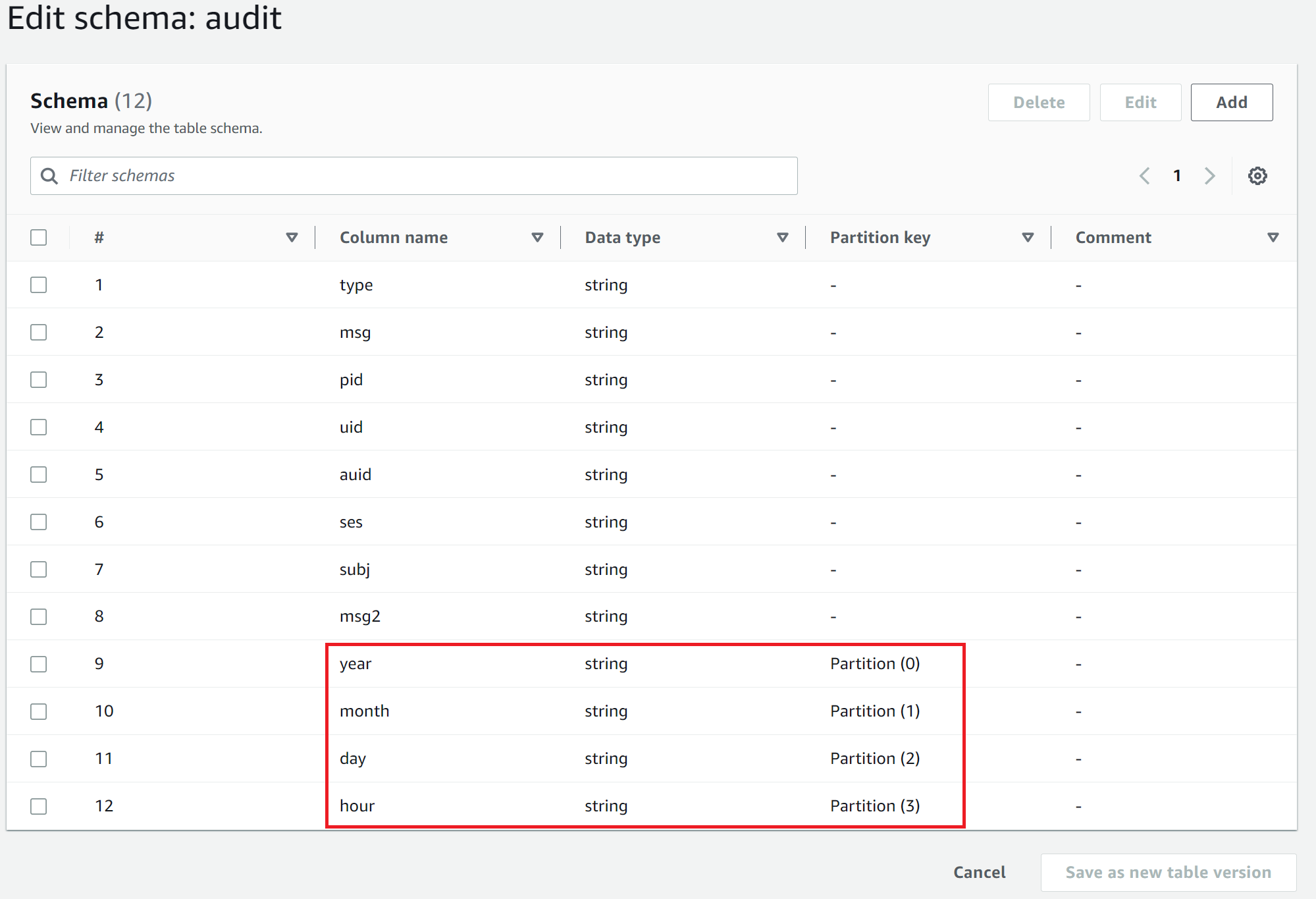
上記で作成したクローラを実行すると、以下の図のようにデータベースにテーブルが作成されます。赤枠は S3① のデータ構造によって Column name が違う値になっているかもしれませんが、この画面から変更することは可能です。
ここまでで、Glue job を利用する準備が整いましたので job を見ていきたいと思います。
Glue job 作成
続いて以下を進めていきます。
2. Glue job でごにょごにょして閲覧可能な状態に加工して S3② へ格納
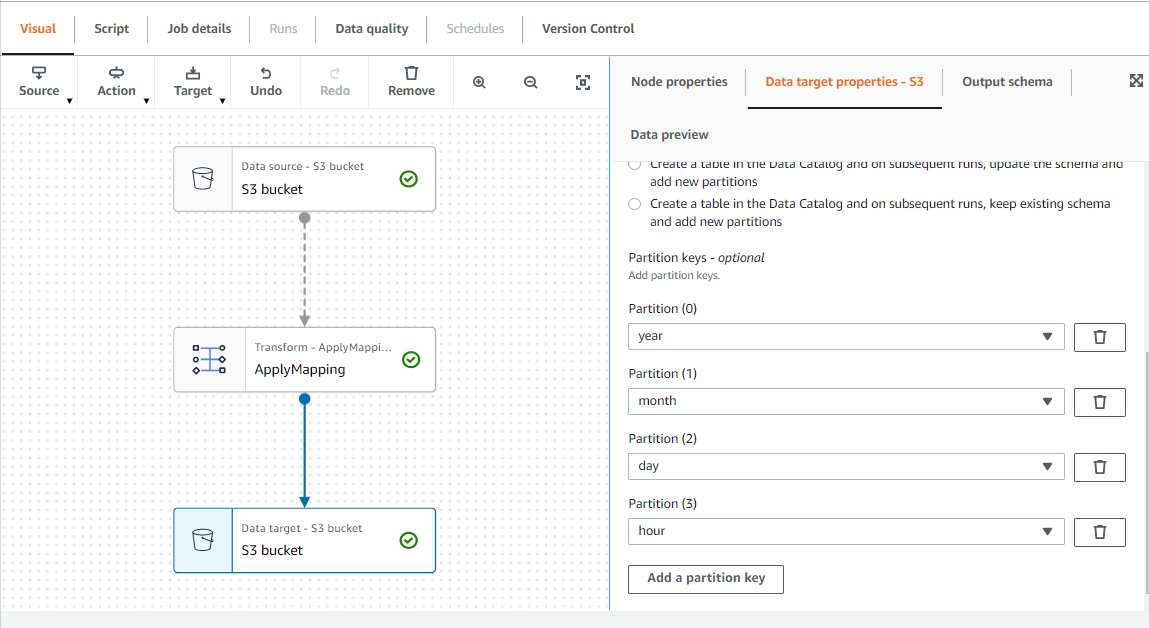
Glue job を作成ボタンを押すと、GUI 上である程度やりたいことを設定することが出来ます。
例えば下記画像だとdata source , transform , data target , Partition などの設定をしています。
その設定に対応したスクリプトが自動で作成されるので、スクリプトを直で修正、又はコンソール上(Glue Studio)で修正をして、加工内容を考えます。以下、今回利用したスクリプトを貼っておきます。まず、スクリプト全体としてどういった処理をしているか簡単に記載します。
- ソースを指定(今回はデータカタログ)
- 各カラム名の修正(今回は修正なし)
- カラム内のデータの整理、型変換
- S3②へのデータ投入&データカタログ②へメタデータ登録
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import lit
from pyspark.sql.types import DateType
from pyspark.sql.functions import col
from pyspark.sql.functions import from_utc_timestamp
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import date_format
from pyspark.sql.functions import split
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
#データカタログをソースに指定
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "syslog", table_name = "audit", transformation_ctx = "datasource0")
#以下設定だと2022/5/15/12のデータをソースに指定することができる(一部のデータのみ読みたい際に利用可能)
#datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "syslog", table_name = "audit", transformation_ctx = "datasource0",push_down_predicate ="(year == '2022' and month == '05' and day == '15' and hour == '12')")
# string で各 field を取得
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("type", "string", "type", "string"), ("msg", "string", "msg", "string"), ("pid", "string", "pid", "string"), ("uid", "string", "uid", "string"), ("auid", "string", "auid", "string"), ("ses", "string", "ses", "string"), (" subj", "string", " subj", "string"), ("msg2", "string", "msg2", "string"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
# dynamic frame → data frame への変換
df = applymapping1.toDF()
#--- audit 特有の変換
# msg から unix タイムを取得する
df = df.withColumn("msg", split(col("msg"), "\\(").getItem(1))
df = df.withColumn("date", split(col("msg"),":").getItem(0))
df = df.withColumn("date", split(col("date"),"\\.").getItem(0))
# date の型変換の実施
df = df.withColumn("timestamp", col("date").cast("Integer"))
df = df.withColumn("timestamp", col("timestamp").cast("Timestamp"))
df = df.withColumn("timestamp", from_utc_timestamp(col("timestamp"), 'JST'))
# split で=を分割
df = df.withColumn("type", split(col("type"), "=").getItem(1))
df = df.withColumn("pid", split(col("pid"), "=").getItem(1))
df = df.withColumn("uid", split(col("uid"), "=").getItem(1))
df = df.withColumn("auid", split(col("auid"), "=").getItem(1))
df = df.withColumn("ses", split(col("ses"), "=").getItem(1))
df = df.withColumn("msg2", split(col("msg2"), "=").getItem(1))
#---- audit 特有の変換
#データが分散されて複数のファイルで出力されてしまうため coalesce メソッドでパーティション数を1にすることでまとめて出力可能
df = df.coalesce(1)
#テスト用
#print(df.show(3))
# dynamic frame へと戻す
applymapping2 = DynamicFrame.fromDF(df, glueContext, "applymapping2")
resolvechoice2 = ResolveChoice.apply(frame = applymapping2, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
# Glue データベースへの登録
sink = glueContext.getSink(connection_type="s3", path="s3://バケット名/audit/",enableUpdateCatalog=True, updateBehavior="UPDATE_IN_DATABASE",partitionKeys=["year", "month","day","hour"])
sink.setFormat("parquet", useGlueParquetWriter=True)
sink.setCatalogInfo(catalogDatabase="syslog-converter", catalogTableName="audit")
sink.writeFrame(dropnullfields3)
job.commit()
Glue job が完成したら、実行することで
- S3② へ parquet 形式でログデータを格納
- S3② をソースにデータベース②にメタデータを登録
ができます。
閲覧
ここまで来ると、後は Athena で集めたデータを見るだけとなります。 Athena からはデータカタログ②を参照して S3② のデータを見に行っています。
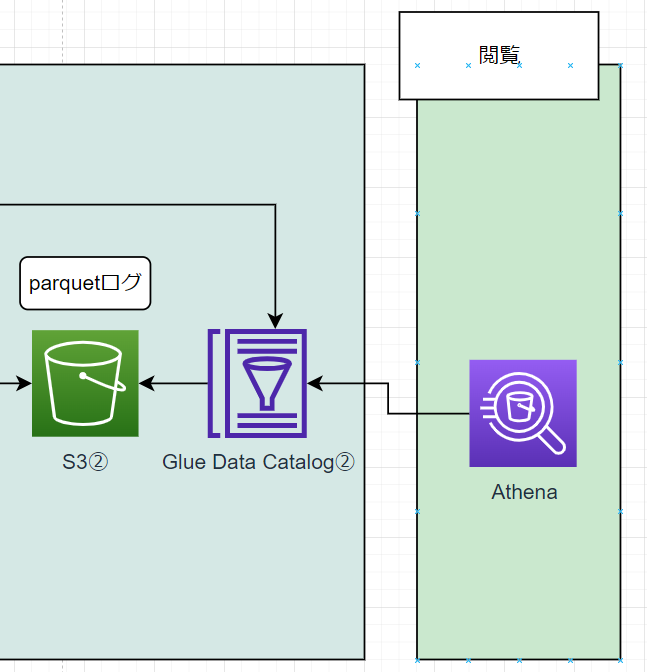
Athena を開き、クエリを実行してみます。
この時に指定するデータベースは Glue Job の後半で作成したもの(今回は syslog-converter )です。
このような形で出力されるようになりました。
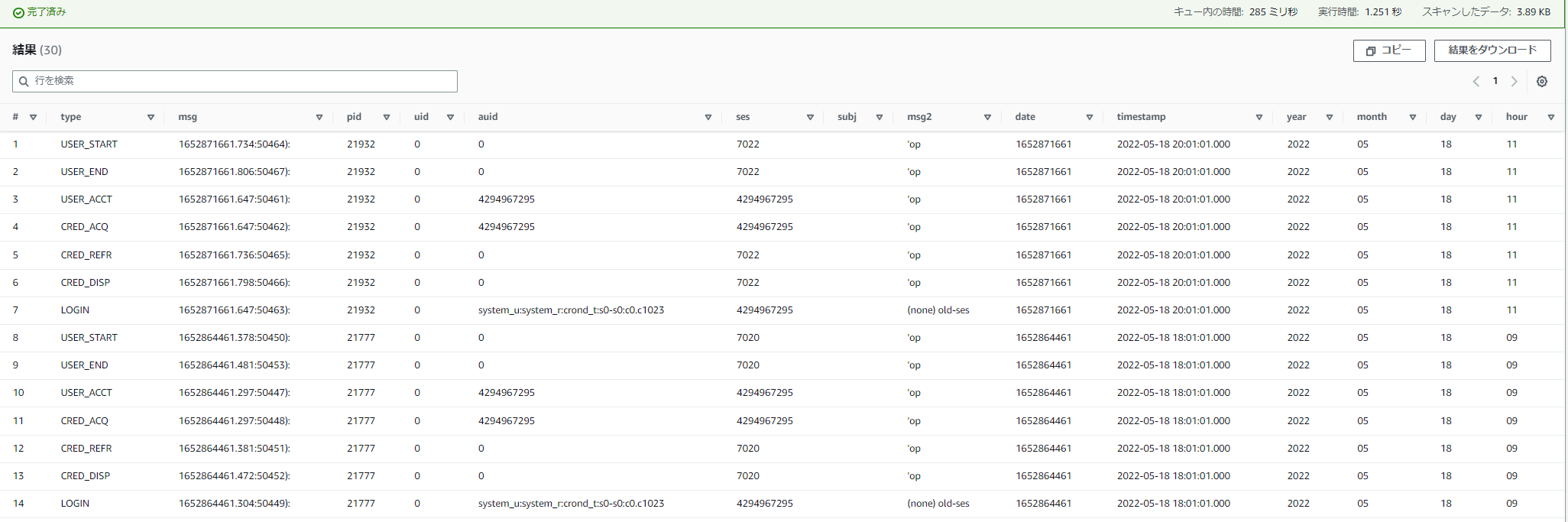
もちろん、不要なデータもあるので用途に合わせてクエリして調整していけたらと考えています。Glue でデータの下準備ができていれば、Athena で簡易的に見る分には楽に閲覧することができそうです。
まとめ
ここまでで、データの収集~閲覧まで順を追ってきました。省略している部分も多少はあるので分かりづらいところもあったかもしれませんが、ログ周りの検証のご紹介でした。
課題として
- ログ毎にスクリプトを調整する必要がある
- 費用面、負荷面の考慮が最適化できていない
などが挙げられます。実運用には程遠いかもしれませんが、個人的には Glue を触ってみることができたので良い機会でした。特に加工周りのデータフローがややこしく理解に時間がかかったので、皆様の参考になれば幸いです。
最後に、私が所属するチームの紹介はこちらです。普段どういうことをしているかなど、気になる方は是非ご覧頂ければと思います!
商標表記
Amazon Web Services, AWS, the AWS logo are trademarks of Amazon.com, Inc. or its affiliates.
The JGraph provided icons and diagram templates are licensed under the CC BY 4.0.
