
シリーズ・すこしずつがんばる streaming data 処理 (2) かんたんな処理の実行

すこしずつがんばる streaming data 処理、前回 からのつづきです。
目指していることの概要などは前回の内容をご覧ください。
いちばんかんたんな pipeline を実装してみる
さて、前回では定形として用意された template 機能から実行してみることで、Dataflow で処理を行うのがどのようなことかの感覚をつかみました。
今回はそこから一歩進んで、想定した仕様にカスタマイズして処理を書くことを目指してみます。
ハッキリ言ってここからが急にしんどいです。何がしんどいかは順に見ていきましょう…
やってみよう
Dataflow のプログラム、というか Apache Beam SDK は (少なくとも初見では) 単純なつくりではなく、かつそれ自体を使うための事前準備が多く必要な類のものです。今回は Java で こちらの document に沿って進めてみます。
環境は、新しめの Java と maven が入ったものがあればよさそうです。構築手順に関しては長くなるのでここでは触れません。
前回利用した、“Word Count” が例というかスタート地点として利用できそうなので、まずは上記 document にあるまま以下のように実行します。
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.46.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
これで、Word Count のソースを含んだ開発環境が手元につくられます。
大量のソースコードが download されます。非常にシンプルなものをつくりたい場合に、ここから必要なものだけを残して使うという作業だけでもちょっとした手間そうなので、もうすこし簡易なスタートがあるといいなと思いました。今回は不要なものは無視して、メインの処理を追ってみましょう。
Word Count のメインの処理は、word-count-beam/src/main/java/org/apache/beam/examples/WordCount.java にすべて書かれています。そんなに量がないのでがまんして眺めてみると、最後に近い場所に以下のように書かれています。
p.apply("ReadLines", TextIO.read().from(options.getInputFile()))
.apply(new CountWords())
.apply(MapElements.via(new FormatAsTextFn()))
.apply("WriteCounts", TextIO.write().to(options.getOutput()));
よく見ると、コード中の 4 つの apply が、前回実行した job の 4 ステップに対応していることがわかります。
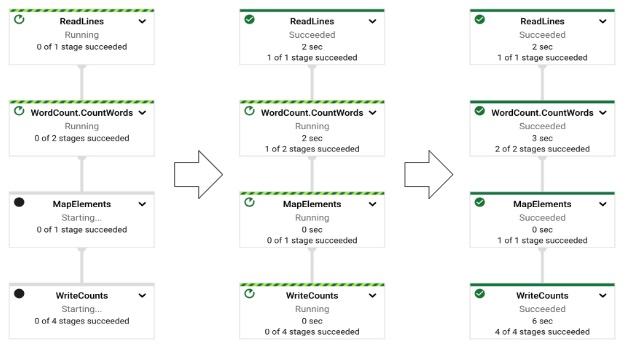
Dataflow は、実装したコードを解析して上記のような、視覚的な表現に自動的に変換してくれ、さらにそこにリアルタイムの処理状況まで表示してくれるのです!
このステップそれぞれを比較しながらこのステップでやっていることは… とコードを追うと、なんとなく Apache Beam での実装のしかた、マナー・ルール的なことがわかってくるのではないでしょうか。とは言え、Java でよく見る通常のプログラムとはちょっと様子が違い、慣れるのになかなか気合が必要です。わたしなどは最初に見たときにこれほんとに Java か?と疑ったほどです。
Apache Beam は、input からデータを受け取り、それを都合のいい単位にまとめて処理に流し、さらに出力する機能も提供してくれるので、実装者に必要な作業をカスタムの実装部分のみにしてくれます。逆に、このために Apache Beam のやりかたに合わせないといけないので、その習得に時間がかかります。最初はやりたいことだけをできるように集中し、それ以外は無視して進めるのがよいかもしれません。
Dataflow 活用の道はほとんど Apache Beam との戦いであり、PTransform とか PCollection、DoFn みたいなものとの戦いと言えるでしょう。しかしそれを越えたら非常に効率的なデータ処理が書けるようになります (と信じています)。がんばりましょう。
手元の PC で実行してみる
それでは、document にある例ほとんどそのままで、一度手元で実行してみましょう。前回やったように、GCP web console 上で見えるように Dataflow 上で実行する (cloud runner) のとは別に、同じ処理を手元で実行することができます。テスト・試行錯誤に便利ですね。
inputFile と output いずれも local を使うことができるようなので、以下のようにして実行します。inputFile は、current directory に適当な英文の text file を用意しておいてください。以下の例では test.txt という名前にしています。
$ cd word-count-beam
$ mvn compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=test.txt --output=counts"
うまくいくと、counts-00000-of-00003 のような file がいくつかでき、中に単語とカウントが出力されたかと思います。
処理の内容を変えてみる
Word Count の処理をもうすこし眺めてみます。
実行結果を見てみますと、単語は分割されているが、大文字小文字はそのままの状態で残っているようです。イマイチ志は低いですが、今回はそれを小文字に揃えるくらいの変更をやってみましょう。
class ExtractWordsFn の method processElement の中に、以下のような部分があります。
for (String word : words) {
if (!word.isEmpty()) {
receiver.output(word);
}
}
ここを、以下のように変更すればなんとなく全部小文字になるような気がします…
for (String word : words) {
if (!word.isEmpty()) {
receiver.output(word.toLowerCase()); // ここを変えただけ
}
}
再度実行してみて、想像したように結果がすべて小文字になっていることを確認します。
これで試行錯誤の準備が整いました。
さらに書きかたを学ぶには…?
はっきり言ってここからが本番でありむしろここまではほんとうにさわりでしかないのですが、ここから Beam programming に馴染んでじぶんのやりたいことの実現方法を身に着けていく必要があり、それがたいへんです。
しかしここまで来たらあとはやりたいことをひとつひとつ、公式 document を見ながら実装していくのが基本かと思います。
Cloud Runner で実行する
ここまでは local で実行してきましたが、前回の記事でやったように、改変したものをクラウド上の Dataflow で実行することももちろんできます。これも GCP document そのまま抜き出しますが、以下のようにします。
$ mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--project=PROJECT_ID \
--gcpTempLocation=gs://BUCKET_NAME/temp/ \
--output=gs://BUCKET_NAME/output \
--runner=DataflowRunner \
--region=REGION"
この場合は当然ですが、inputFile や output に local file は使用できないので GCS 上の path を指定しましょう。
GCP IAM 権限
指定しなければ、Dataflow worker は Compute Engine default service account を使用します。
上記の例では実行する際の service account に、ざっくり Pub/Sub Subscriber、GCS bucket への読み書き権限あたりが必要です。
こちら では例として、Project Owner Role をつければ動作するが、production 用にはもっと細かく制御をすべしと書かれています。詳しくは細かくなってしまうので割愛させてください。(世の中にたくさん例がありそうです)
Dataflow worker service account については こちら に詳しく説明がされています。
まとめ
駆け足気味ですが、Apache Beam で実装した pipeline でデータ処理を実装・動作確認するまでをやってみました。Beam を使いこなせるようになるには、やりたいことを明確にして実装にするまでの検討・試行錯誤をかなり繰り返して慣れる時間が必要そうです。
今回は、たいへんだーばかりの感想になってしまいましたが、引き続きがんばります 🚀
