
[上級] ハマグリ式! Terraform での transpose 関数の使いみち
はじめに
この記事を見つけたけど、後で見ようと思ったそこのあなた!
ぜひ下のボタンから、ハッシュタグ #ハマグリ式 でツイートしておきましょう!

こんにちハマグリ。貝藤らんまだぞ。
今回は AWS および Terraform の上級者向けに、ハマグリ式! Terraform での transpose 関数の使いみちをご紹介します!
上級者って?
ハマグリ式では、下記のようにレベルを設定しています。
- 初級者:初めてクラウドサービスを利用する人で、基本的な操作(例:ファイルの保存や、サーバーの起動)をインターフェースを通じて行うことができます。また、シンプルなセキュリティルールの設定や、一部の問題のトラブルシューティングに対応できます。
- 中級者:より深い知識を持ち、コードを用いて操作を自動化したり、より複雑なタスク(例:自動でサーバーの数を増減させる)を行います。また、より高度な監視や、全体のシステム設計と実装について理解があります。
- 上級者:幅広く深い知識を持ち、大規模で複雑なシステムを設計、実装、維持する能力があります。最先端のテクノロジーを活用し、安全性、耐障害性、効率性を最大化するためのソリューションを提供します。
なお上記は ChatGPT による出力ですが、この記事でほかに生成 AI によって出力された文章はありません。ただし、Terraform や Python などのコードは生成 AI の出力を一部利用しています。
ハマグリ式って?
貝藤らんまが作成するブログ記事のブランド名です。あまり気にせず読み飛ばしてください。
何を書くの?
以下の通りです。
- この記事で扱うツール
$ terraform --version
Terraform v1.5.3
on linux_amd64
+ provider registry.terraform.io/hashicorp/aws v5.7.0
$ python --version
Python 3.10.6
- この記事で書くこと
- AWS を例とした、Terraform での
transpose関数の使いみち (効果的な Terraform 設計)
- AWS を例とした、Terraform での
- この記事で書かないこと
- Terraform 組み込み関数の仕様説明
- Terraform の基礎
- Terraform のディレクトリデザイン
- サンプルコード
- 構築のベストプラクティス
免責事項
- この記事に書かれていることは弊社の意見を代表するものではありません。
- この記事に書かれていることには一定の調査と検証を実施しておりますが、間違いが存在しうることはご承知おき下さい。
Terraform での transpose 関数の使いみち
Terraform に便利な組み込み関数がたくさんあることは皆さんご存知かと思います。
しかし Terraform の Built-in Functions ドキュメントを眺めてみると、「この関数、どんなときに使うんだ……?」と困惑する関数が多々あることでしょう。
ないですか?
え、そもそも「組み込み関数」がわからない?
組み込み関数使わない……ってこと?
便利な Terraform Function の使い方3例
わかりました。
そこまで言うなら!
transpose について考える前に、先に3つほど組み込み関数の便利な使い方をご紹介しましょう。
仕様はドキュメントに書いてある通りなので説明を割愛するぞ。
lookup
lookup はざっくり説明すると「指定したキーがあればその値を使う、なければデフォルト値を使う」ような関数です。
したがって「基本的にはこれ、一部はこっち」という指定の仕方をする引数に使うと便利です。
たとえば、大多数の EC2 インスタンスはインスタンスタイプに t3.small を使うことになっているとき、
resources "aws_instance" "example" {
for_each = var.ec2
instance_type = lookup(each.value, "instance_type", "t3.small")
}
たとえば環境ごとに段階的に Aurora のエンジンバージョンを上げていくとき、
resource "aws_rds_cluster" "example" {
for_each = var.aurora
engine_version = lookup(each.value, "engine_version", "8.0.mysql_aurora.3.03.1")
}
などの使いみちが考えられます。
contains & keys
contains と keys の組み合わせは、実例を見るのがわかりやすいでしょう。
たとえば、EC2 インスタンスでインスタンスタイプが指定されているのは本番環境なので、削除保護をかけるというときに使えます。
resources "aws_instance" "example" {
for_each = var.ec2
instance_type = lookup(each.value, "instance_type", "t3.small")
disable_api_termination = contains(keys(each.value), "instance_type") ? true : false
}
他の引数に伴って値が変わることを前提としているときに使えますが、lookup よりは頻度が少ないでしょう。
length & regexall
たとえば Python では "ex" in "example" と書けば True になり、文字列が含まれているかを判定できます。
Terraform ではそういった記述ができないどころか、関数さえ用意されていません。
なので length と regexall の組み合わせを使うことになります。
これは ドキュメント にも書かれていて、以下のようになります。
length(regexall("[a-z]+", "123456789")) > 0
transpose 関数の使いみち
さて本題の transpose 関数です。
この関数はざっくり説明すると「与えられた list の map に対し、キーとバリューを入れかえた map を返す」です。
詳細な説明
ざっくり説明すると楽なのですが、使い道を考えるにあたってここはちゃんと説明しておきます。
transpose は以下のような処理をする関数です。
- 入力した map A の値である、それぞれの list 内の要素を、重複を除いて抽出する
- 抽出した要素それぞれが各キー k_B となる map B を生成する
- 生成した map B のキー k_B が含まれていた、入力した map A の list のキー k_A をすべて抽出する
- 抽出したキー k_A を list 化して、抽出に使った map B の k_B の値にする
たとえば
locals {
A = {
a = ["x", "y"]
b = ["y", "z"]
}
}
は
locals {
B = {
x = ["a"]
y = ["a", "b"]
z = ["b"]
}
}
となります。
この関数が使えそうな場面はどこでしょうか。
抽象的に書くと、「リソースで設定をリストし、そのリストに対応するリソースから逆にキー側のリソースを参照する」でしょうか。
なるほど、完全に理解したぞ。
もっとちゃんと考える
とはいえまだピンと来ないので、transpose いわゆる転置の意味を考え直そうと思います。
本来、転置は行列という考え方でよく使われる用語かと思います。
map A を行列で表現してみましょう。
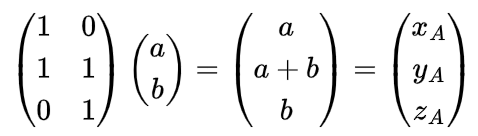
これを転置すると、次のようになります。
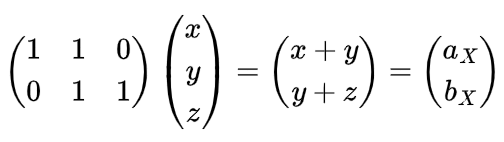
このように、(a b) から (x y z) への関係を示す行列が、転置することで (x y z) から (a b) への関係を示す行列に変わりました。
ということで、 transpose は「二者の関係を仲介する」行列へ適用することで活用できそうです。
※以後、この「二者の関係を仲介する」行列を「表現行列」と呼ぶことにします。
今度こそ完全に理解したぞ。
(a b) と (x y z) の次元が一致するとき
ただし (a b) と (x y z) の次元が一致するときはちょっと注意が必要でしょう。
このとき表現行列は縦と横の要素数が同じ、いわゆる正方行列となります。
ところで Terraform で「転置を使う」というのはどういうシチュエーションかイメージしてみましょう。
そもそも Terraform で「関数を使う」というモチベーションはほぼ「書く量を減らしたい」というもののはずです。
ということは書く量が減らない、つまり「書く必要がなかった」となるような転置は必要がありません。
したがって表現行列が「なんか対称的だな」と思ったら、同時に「なんかおかしいな」と思うべきです。
たとえば表現行列が
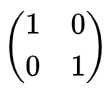
のとき、map A, B は
locals {
A = {
a = ["x"]
b = ["y"]
}
B = {
x = ["a"]
y = ["b"]
}
}
となるので、転置の意味がまるでない結果となります。
まあナナメが1ならやめとけということだぞ。
ちょっと細かい話
これは数学的には表現行列の逆行列が元と同じいわゆる対合行列になっているためだと思いますが、専門外なので触れないでおきます。
ただし逆行列を意識すると
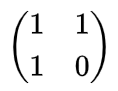
はアリだな、と判断できるのでよいかもしれません。
???
output で利用
前置きが長くなりましたが、具体的にどう使うことができるかを考えていきましょう。
Terraform の特に AWS まわりではお互いを指定しあう必要があるリソースは基本的に無いかと思います。
なのでもっともシンプルな利用方法は output で状況を把握する、といったことが多いでしょう。
たとえば IAM の group に user を割り当てるような Terraform コード上で下記のように書いたとします。
locals {
iam_group = {
A = [user_a, user_b]
B = [user_b, user_c]
}
}
しかしドキュメント作成のために「ユーザーがどのグループに所属しているか」という情報がほしいということもあるかもしれません。
そういった場合には
output "user_to_group" {
value = transpose(local.iam_group)
}
とすれば一発です。
便利だなぁ~。
でもやっぱりリソースで活用したい……と思いませんか?
せっかく Terraform を使っているからにはリソースへ組み込み関数を使っていきたいですよね!
活用できるリソースを見つけ出す
さてこの transpose 、リソースへはどのように使えそうでしょうか。
まず先ほど書いたように Terraform の特に AWS まわりではお互いを指定しあう必要があるリソースは基本的に無いので、3つ以上のリソースに対して使うことを考えます。
単純に表現行列を使うと、下図のようにリソース B, C それぞれに対してリソース A を割り当てることができます。
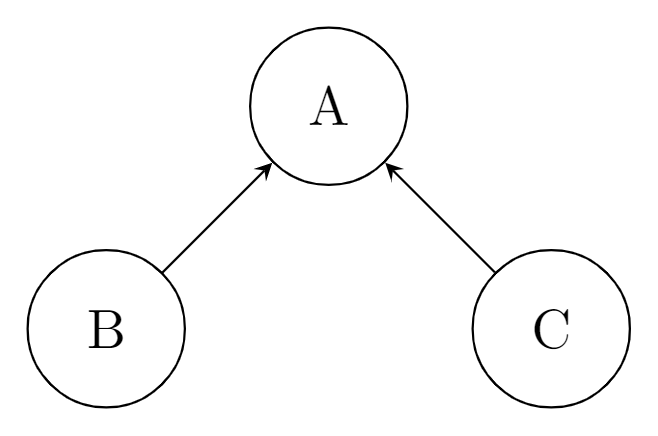
このときの表現行列が B と C の間の関係を表していることになれば、インフラの状態を見やすくすることができます。
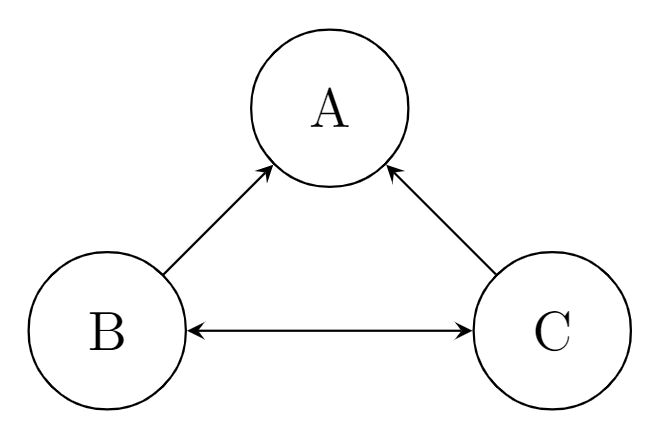
この状態は
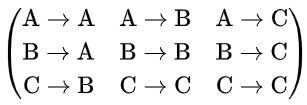
というフォーマットで、その方向に依存があれば1、なければ0のようにマッピングできるでしょう。
A, B, C の順番が固定されていないとすれば、下記のいずれかで表すことができます。
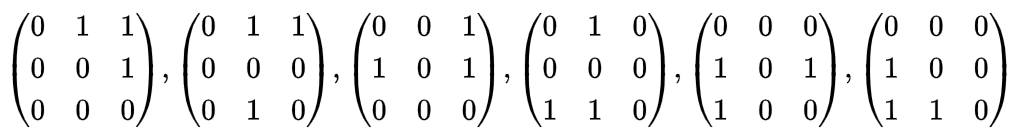
なおこの行列は ChatGPT を活用して作成した下記のプログラムで導出しました。
# graph_transformer.py
import numpy as np
import itertools
# ラベルの順序を変更する関数
def change_order(matrix, labels, new_order):
# 新しい順序に基づいてインデックスを取得
index = [list(labels).index(i) for i in new_order]
# 行と列を並び替え
matrix = matrix[:, index][index]
return matrix, new_order
# 全ての順序の組み合わせで行列を生成する関数
def generate_target_matrices(matrix, labels):
target_matrices = []
for order in itertools.permutations(labels):
new_matrix, _ = change_order(matrix, labels, order)
target_matrices.append(new_matrix)
return target_matrices
# スクリプトとして実行された場合の処理
if __name__ == "__main__":
# 関係性行列の定義
matrix = np.array([[0, 1, 1], # A から B, C への関連性
[0, 0, 1], # B から C への関連性
[0, 0, 0]]) # C からの関連性はなし
# ラベルの定義
labels = np.array(['A', 'B', 'C'])
# 全ての順序の組み合わせで行列を生成
target_matrices = generate_target_matrices(matrix, labels)
# 新しい行列とラベルを表示
for matrix in target_matrices:
print("Order: ", labels)
print(matrix, "\n")
これを目標行列と呼ぶことにします。
※いわゆる「隣接行列」の「二値行列」と呼ぶらしいですが、専門外なので触れないでおきます。
一方で、たとえば VPC 関連リソースの一部について、関係性を行列にすると以下のようになるはずです。


この行列は「特定のリソースの種類に対する、リソース間の関係」ではなく、「リソースの種類の間の依存関係」をマッピングしたものなので、関係行列と呼ぶことにしておきます。
なお赤字部分は route リソースが route_table, route_table_association リソースを介して subnet リソースへ紐づくので、ちょっと端折って1としています.
この関係行列から任意の3リソースについて抽出した3x3の行列を作成し、目標行列と一致したものが transpose の活用できる組み合わせであると言えます。
これは ChatGPT を活用して作成した下記のプログラムで導出します。
import numpy as np
import graph_transformer
# 元の行列の定義
original_matrix = np.array([
[0, 0, 1, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]
])
# ラベルの定義
labels = [
"aws_subnet",
"aws_internet_gateway",
"aws_nat_gateway",
"aws_route_table",
"aws_route_table_association",
"aws_route",
"aws_security_group"
]
# 探索したい行列
matrix = np.array([[0, 1, 1], # A から B, C への関連性
[0, 0, 1], # B から C への関連性
[0, 0, 0]]) # C からの関連性はなし
# graph_transformer.pyから行列を生成
target_matrices = graph_transformer.generate_target_matrices(matrix, labels[:3])
print("Target matrices:")
for target_matrix in target_matrices:
print(target_matrix)
# すべての組み合わせで試し、目的とする行列が見つかったらそのラベルの組み合わせを表示
for target_matrix in target_matrices:
for i in range(original_matrix.shape[0]):
for j in range(i+1, original_matrix.shape[0]):
for k in range(j+1, original_matrix.shape[0]):
sub_matrix = original_matrix[[i, j, k]][:, [i, j, k]]
if np.array_equal(sub_matrix, target_matrix):
print(f"Found a target matrix at labels {labels[i]}, {labels[j]}, {labels[k]}")
結果としては、aws_subnet, aws_nat_gateway, aws_route の組み合わせが対象となりました。
したがって下記のような NAT ゲートウェイ作成時の活用が考えられます。
locals {
subnet = {
public = {
a = "10.0.0.0/24"
c = "10.4.0.0/24"
}
private = {
a = "10.8.0.0/24"
c = "10.12.0.0/24"
}
}
nat_gateway = {
a = ["a","c"]
}
}
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public" {
for_each = local.subnet.public
vpc_id = aws_vpc.main.id
availability_zone = "ap-northeast1${each.key}"
cidr_block = each.value
}
resource "aws_eip" "nat_gateway" {
for_each = local.nat_gateway
}
resource "aws_nat_gateway" "main" {
for_each = local.nat_gateway
allocation_id = aws_eip.nat_gateway[each.key].id
subnet_id = aws_subnet.public[each.key].id
}
resource "aws_route_table" "private" {
for_each = local.subnet.private
vpc_id = aws_vpc.main.id
}
resource "aws_route" "private" {
for_each = local.subnet.private
destination_cidr_block = "0.0.0.0/0"
route_table_id = aws_route_table.private[each.key].id
nat_gateway_id = aws_nat_gateway.main[transpose(local.nat_gateway)[each.key][0]].id
}
こうすることで、下図のように NAT ゲートウェイとルートの関係を表すことができます
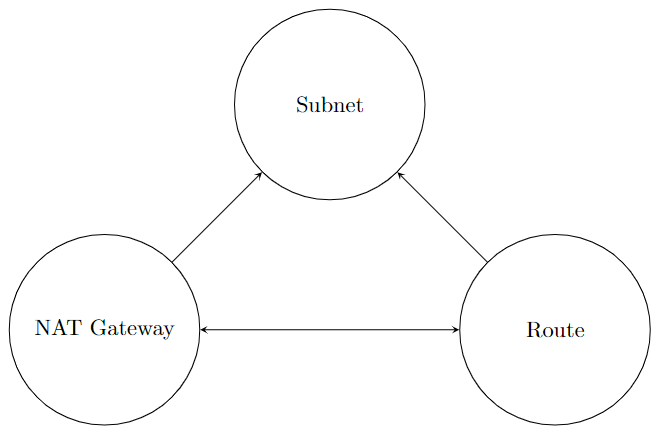
このときのサブネットの表現行列は
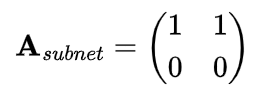
のようになるでしょう。
え、これだけ……?
実務でどう使っている?
今回いろいろ考えてみましたが、ぶっちゃけ transpose は実務でまったく使っていません。
必要が無ければ使わなくていいです。もちろん行列とか一切考えたことはありません。
というわけで、「output 以外で transpose を使いたくなったらちょっと考え直したほうがいい」ということでしょう!
あまり考えず output だけで使っておこう!
まとめ
まとめは ChatGPT に箇条書きでお願いしようと思います。
以上のブログ記事のまとめを箇条書きで書いてください
記事の著者が語っている体の、ですます調で書いてください
- Terraformの組み込み関数には、使いみちが明確でないものが多く存在します。
- lookup関数は、指定したキーの値を使用するか、なければデフォルト値を使用するための関数です。
- containsとkeysの組み合わせは、特定の条件下で値が変わる引数に使用すると便利です。
- 文字列が含まれているかを判定するには、lengthとregexallの組み合わせを使用します。
- transpose関数は、与えられたリストのmapに対して、キーとバリューを入れ替えたmapを返します。
- transpose関数は、「リソースで設定をリストし、そのリストに対応するリソースから逆にキー側のリソースを参照する」場面で使えます。
- transpose関数は、二者の関係を仲介する表現行列に適用することで活用できます。
- transpose関数を使う最もシンプルな利用方法は、Terraformのoutputで状況を把握することです。
- 3つ以上のリソースに対してtranspose関数を使う場合、リソースBとCそれぞれに対してリソースAを割り当てることが可能です。
- 実際の業務では、transpose関数はあまり使われていないとのことです。必要がなければ使わない方が良いでしょう。
ぜひ下のボタンから、ハッシュタグ #ハマグリ式 で感想をツイートしてください!
今後ともハマグリ式をどうぞよろしくお願いいたします!