
必要なぶんだけ GPU を使いたい。Kubernetes でやってみよう

こんにちは、ホシイです。
貧乏性なので、仕事中はたいてい費用のことを考えています。
今回は、機械学習インフラにも関連する記事です。AI に関しては SQUARE ENIX AI 技術ブログ もありますので、ご興味がありましたらぜひご覧ください!
GPU をお安く、好きなときに好きなだけ利用したい
AI の話題花盛りの昨今、アプリケーションで GPU を利用する機会も増えてきました。GPU の用途もいろいろとありますが、最近でわたし周辺の需要として特に多いのは、機械学習です。ざっくり言うとタスクに対してパラメーターやデータを与えてある程度の時間、計算処理をするものです (なんでもそうと言えばそうですが)。ここでの問題は、GPU は基本的に高価で購入することに敷居があるうえに、それをホストに組み込んでかつ共有リソースとして利用するというのはなかなか難しいというものです。
今回の記事ではこれをスマートに解決する例をつくってみたいと思います。GKE Autopilot で。
最初は Cloud Run を調べたのですが、通常の Cloud Run では GPU が使えないようでした 1 (GKE node を使えばできそう)。GPU が使える選択肢として考えられる GCE や GKE Standard では、ゼロから scale させる仕組みをつくりたいとなると、追加の工夫が必要そうです。GKE Autopilot では cluster を常時維持する必要はありますが、GPU 含めてリソース管理するシステム費用と考えるとじゅうぶん妥当な費用と感じます。
※ Vertex AI を使え… という声が聞こえてきますが、ここでは聞こえないこととします。GCP 以外でもいろいろと便利なサービスはあるぞ!というかたは、どこかでお会いしたときに教えてください 🙏
ちなみに今回の記事、かなり類似した内容がこちら → GKE で GPU 使うのめっちゃ簡単 (Google Cloud Uchimaさんの記事) にあるのを観測しております。Autopilot などについてはそちらで詳しく説明されていますので、あわせてご参照ください。
想定アプリケーションシナリオ
今回は、以下の仮想要件向けにソリューションをつくってみましょう。
エンドユーザーには web UI を提供し、その操作に応じて機械学習の処理を実行するアプリケーションとします。このとき、リクエストを受け付けるために web アプリケーションの Pod は常時起動しておく必要がありますが、機械学習の処理は GPU を使用するため、それと同居するとクラウド費用が高額になってしまいます。ということで、機械学習処理は web からは分割して、使うときだけ起動するようにします。
(データセットやモデルなどの扱いは今回のスコープからはずし、完全に省略します)
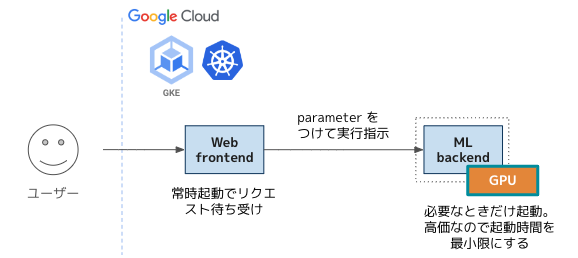
こうすることにより、web Pod は必要最小限の CPU・メモリ要件に絞りつつ、機械学習 Pod には最適な GPU やその他要件が盛り込めます。
サンプルコード
今回は、web app が Python で書かれている想定で、そこから直接 GPU を利用する Pod を生成する実装を例として置いておきます。
コメントがあまり入っていませんが、よく見てみると Job の manifest yaml を上から順に Python で書いているようなものなので、書き方さえわかればあまり迷うところは無さそうです。
- 実行環境 (Pod) で Job を生成する権限を持っている前提です。
- 処理的には
kubernetesmodule を使用し、Job リソースの定義を作成するだけです。 - Job の定義として、GPU を使用するように指定しています。
- 汎用 container image と動作確認用の command を入れていますが、実用時はここを差し替える想定です。
def create_job(ns: str):
from kubernetes import client, config
# 認証情報を load する
try:
config.load_kube_config()
except:
config.load_incluster_config()
# 順に Job の定義をつくっていく
container = client.V1Container(
name="app",
image="nvidia/cuda:12.2.0-runtime-ubuntu22.04",
command=[ "/bin/bash", "-c", "--" ],
args=[ "pwd && ls -l / && nvidia-smi" ],
resources=client.V1ResourceRequirements(
limits={
"cpu": "500m",
"memory": "2Gi",
"nvidia.com/gpu": 1
}
))
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(labels={"app": "test"}),
spec=client.V1PodSpec(
restart_policy="Never", containers=[container],
node_selector={
"cloud.google.com/gke-accelerator": "nvidia-tesla-t4",
"cloud.google.com/gke-spot": "true"
}
))
spec = client.V1JobSpec(
template=template,
backoff_limit=0,
ttl_seconds_after_finished=60)
job = client.V1Job(
api_version="batch/v1",
kind="Job",
metadata=client.V1ObjectMeta(name="test-1"),
spec=spec)
# 指定された namespace に Job を生成する
batch_v1 = client.BatchV1Api()
api_response = batch_v1.create_namespaced_job(
body=job,
namespace=ns)
print("Job created. status='%s'" % str(api_response.status))
if __name__ == "__main__":
create_job("test-gpu")
Autopilot なので、Job が生成されてから Pod が Running になるまで数分かかります。のんびりと待ちましょう。
以下のように、-w で watch すると Pod 状態の遷移が確認できます。
❯ kubectl get po -n test-gpu -w
NAME READY STATUS RESTARTS AGE
test-1-zyfbc-9z89w 0/1 Pending 0 6s
test-1-zyfbc-9z89w 0/1 Pending 0 4m26s
test-1-zyfbc-9z89w 0/1 ContainerCreating 0 4m26s
test-1-zyfbc-9z89w 1/1 Running 0 5m29s
うまく実行されると、nvidia-smi の出力が確認できるハズです。参考までに、実際の環境で実行した出力を載せておきます。(以下は container から手動で実行したものです)
root@test-1-zyfbc-9z89w:/# nvidia-smi
Tue Dec 5 07:10:38 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.182.03 Driver Version: 470.182.03 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
まとめ
使い慣れた Kubernetes のツールを使い、スケーリング・費用最適化を意識して GPU を使った workload に対応できました。
今回は GKE Autopilot を使って必要なぶんだけ GPU つきの node を provision してもらうようにしましたが、オンプレ Kubernetes などですでに GPU つきの node がある場合は、そこに Pod が schedule されるように変更するだけで同様に柔軟なスケーリングができそうです。
次は Vertex AI も検討して、さらなる運用工数の削減や開発体験の改善を目指していきたいと思います。(願望)
