
共有サーバーの NVIDIA GPU monitoring をお手軽に
こんにちは、ホシイです。
機械学習が業務に入り込んで、GPU つきの PC やサーバーを共有機として使用することが増えました。以前から自動テスト等の用途で需要はあったかと思いますが、急速に進んでいるように感じます。
今日は、こうやって増えてきたホストの GPU のみなさんが、元気よく働いている様子を確認しやすくする仕組みを用意してみたいと思います。
Observability に関しては以前、JMX MBean metrics の可視化を試す を書きました。また、Cloud Monitoring で custom metrics を活用する という記事で、CLI output を parse して custom metrics 化についても書いています。
今回もこのあたりの仕組みを使い、custom metrics をつくればできそうだな… と思っていました。nvidia-smi も、よく見る人間に読みやすい形式だけではなく monitoring ぽい出力にも対応しているようですし。
しかし!web 検索していると、やはりみんなホシイと思っているものはすでにつくられているものです。今回はそちらをありがたく利用させていただくことにしましょう。
NVIDIA DCGM Exporter を使用して GPU の monitoring をしてみるサンプル
NVIDIA 社が DCGM Exporter という、Prometheus 等に metrics を収集させるためのソフトウェアを提供しています。GitHub 上の repo を確認すると、license は Apache License 2.0 とありました。
冒頭にも書きました 以前の記事 の内容も流用し、Docker compose を使って Prometheus + Grafana とともに この exporter を使い、情報の可視化をしてみましょう。
以下のような構造にしています。
workspace
├─ compose.yaml
└─ prom-data
└─ prometheus.yaml
確認に使用したふたつのファイル内容もここに置いておきます。
version: "3.7"
services:
dcgm-exporter:
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.3.0-3.2.0-ubuntu22.04
ports:
- "9400:9400"
cap_add:
- SYS_ADMIN
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
prometheus:
image: prom/prometheus
command: --config.file=/prometheus-data/prometheus.yaml
ports:
- "9090:9090"
volumes:
- ./prom-data:/prometheus-data
grafana:
image: grafana/grafana
ports:
- "3000:3000"
global:
scrape_interval: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: 'dcgm'
static_configs:
- targets:
- dcgm-exporter:9400
起動する
docker compose up -d
Grafana へは http://localhost:3000/ でアクセスします。初期設定では user: admin password: admin で sign in できます。
web UI にアクセスできたら、Data source に Prometheus を選択し http://prometheus:9090 (docker compose network 上で hostname が prometheus になっているので) を設定します。
Dashboard をつくる
これで Grafana で各種 metrics が参照可能になりました。あとは Grafana 職人的に dashboard をつくるだけです。…が。
公式 GitHub repo に、NVIDIA DCGM Exporter Dashboard が紹介されています。こちらを import することで、すぐにそれっぽいものができてしまいました。
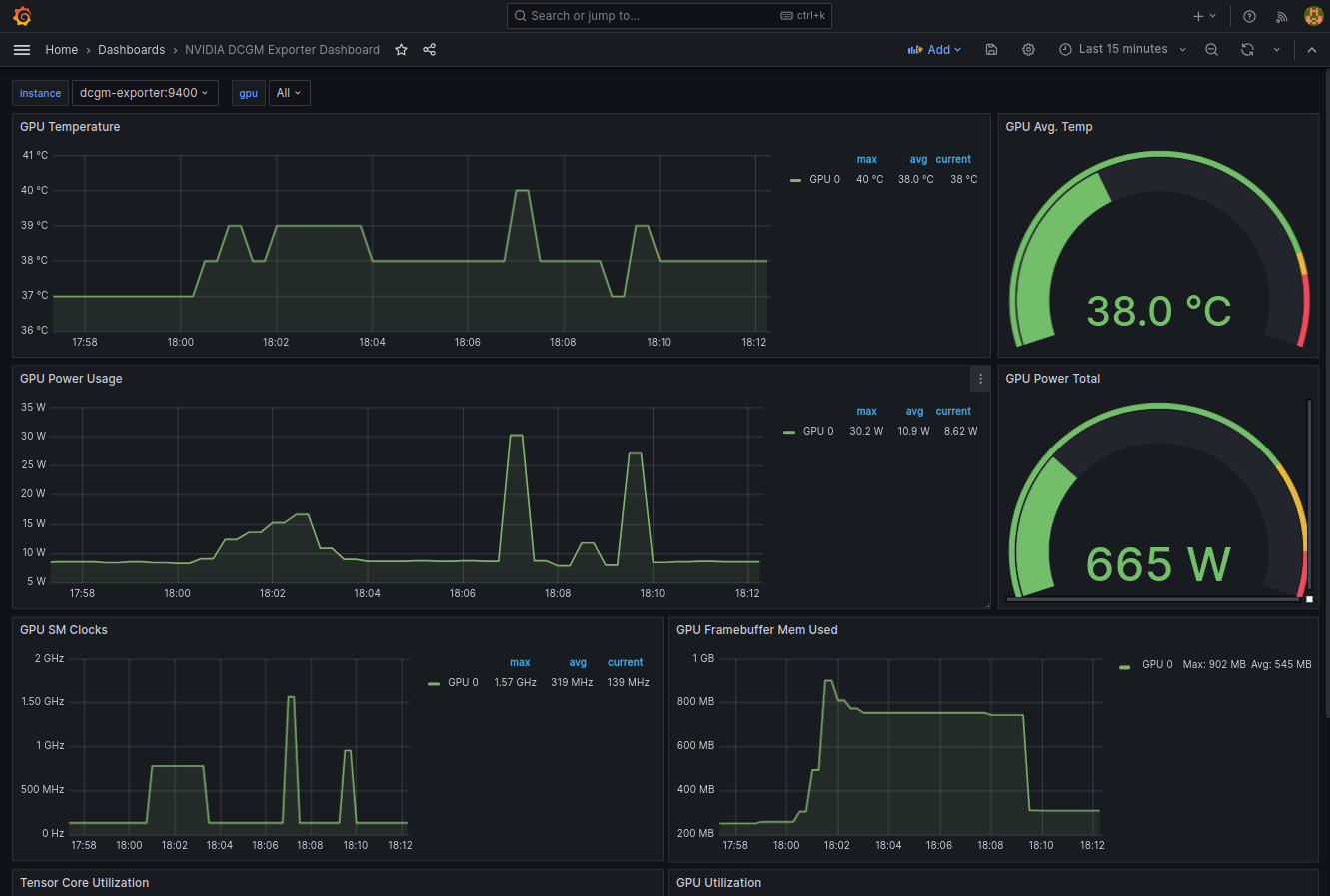
それっぽいですね!
VS Code Server を使用して別の host 上で開発する
おまけです。
今回、いつも使っている開発用のノート PC と GPU がついている target PC が別だったので、VS Code の Remote - Tunnels extension を使用してみました。
導入手順に関しては こちら に詳しく説明されているのでここでは省きます。準備としては、以下が必要でした。CLI なども説明がじゅうぶんに表示されるので、案内された通りに進めれば特別迷うところは無さそうです。試したところでは、GitHub account または Microsoft account が必須なようでした。
- target PC
- VS Code、または code CLI を install する
code tunnel
- client PC
- extension
Remote - Tunnelsを install する Remote Tunnels: Connect to Tunnelを実行して、接続先を指定する。
- extension
使用してみた感想としては、editor はいつも通り使えるものの、Terminal はかなり遅延を感じました。ただ、target 側で開発しているソースを自然と開いて編集できたり、Terminal においても client の Linux 機から target の Powershell が何も考えずに使用できるというのは非常に強力です。共有機として使用している PC を使う際にはとても便利に使えそうです。
まとめ
GPU つきサーバーの監視ソリューションをつくってみました。
DCGM Exporter を監視対象のホストに入れておき、Prometheus へ metrics を収集し、Grafana で柔軟に metrics dashboard の作成・公開できます。
しかも、今回はほとんどコードも書いていません。便利な世の中や… 🤗
Troubleshooting
上に掲載した設定はすべて解決済みのものですが、試している間に出会ったエラー出力を参考に貼っておきます。
dcgm-export が起動するまで
PS C:\gpu-mon> docker logs gpu-mon-dcgm-exporter-1
Warning #2: dcgm-exporter doesn't have sufficient privileges to expose profiling metrics. To get profiling metrics with dcgm-exporter, use --cap-add SYS_ADMIN
time="2023-12-18T11:41:05Z" level=info msg="Starting dcgm-exporter"
Error: Failed to initialize NVML
time="2023-12-18T11:41:05Z" level=fatal msg="Error starting nv-hostengine: DCGM initialization error"
出力にある通り、以下を compose.yml に追加しました。
cap_add:
- SYS_ADMIN
また、NVIDIA の GPU が無いマシンで実行すると以下のエラーになりました。driver が入っていないなど、適切に configuration されていない場合もこうなるかもしれません。OS で正常に認識されているかなどをまず確認するとよさそうです。また、container 環境によっては NVIDIA Container Toolkit を自前で入れる必要があるかもしれません。
PS C:\gpu-mon> docker logs gpu-mon-dcgm-exporter-1
time="2023-12-18T11:45:00Z" level=info msg="Starting dcgm-exporter"
Error: Failed to initialize NVML
time="2023-12-18T11:45:00Z" level=fatal msg="Error starting nv-hostengine: DCGM initialization error"
参考: 起動に成功したときの log
PS C:\gpu-mon> docker logs gpu-mon-dcgm-exporter-1
time="2023-12-18T11:46:35Z" level=info msg="Starting dcgm-exporter"
time="2023-12-18T11:46:35Z" level=info msg="DCGM successfully initialized!"
time="2023-12-18T11:46:35Z" level=info msg="Not collecting DCP metrics: This request is serviced by a module of DCGM that is not currently loaded"
time="2023-12-18T11:46:35Z" level=info msg="No configmap data specified, falling back to metric file /etc/dcgm-exporter/default-counters.csv"
time="2023-12-18T11:46:35Z" level=info msg="Initializing system entities of type: GPU"
time="2023-12-18T11:46:36Z" level=info msg="Initializing system entities of type: NvSwitch"
time="2023-12-18T11:46:36Z" level=info msg="Not collecting switch metrics: no switches to monitor"
time="2023-12-18T11:46:36Z" level=info msg="Initializing system entities of type: NvLink"
time="2023-12-18T11:46:36Z" level=info msg="Not collecting link metrics: no switches to monitor"
time="2023-12-18T11:46:36Z" level=info msg="Pipeline starting"
time="2023-12-18T11:46:36Z" level=info msg="Starting webserver"
Metrics があらわれない
Prometheus で見ても metrics が出力されていないな… と少し困っていたのですが、local PC の時計が狂っていたというつまらない問題でした。Windows で実験していたのですが、Linux と dualboot で使っており、こちら デュアルブート時のLinuxとWindowsの時刻ズレを解消する でなおるものと思われます。めんどくさくて放置しています…
