
Spanner change stream を streaming 処理する

データベースの変更に対して非同期で処理を追加したい
こんにちは、ホシイです。
サーバーアプリケーションをつくっていて、あるデータが追加されたり変更されたときに、別の処理を追加したいということがよくあります。アプリケーションの実装を変更してそこに直接処理を追加することも出来ますが、その改修自体が難しかったり、テストの工数がとれなかったり、負荷増大につながる懸念があったりといった問題はよくついてまわるものです。
追加の処理が元の処理とおなじトランザクション内にある必要がない・多少遅れても問題ないといった場合は、外部的な非同期処理として追加する手法もよく用いられます。
たとえば、ユーザーが新規追加された後、ほぼリアルタイム (通常数秒〜 遅れくらいの期待値) でアイテムボックスに歓迎アイテムをプレゼントする、みたいなことに使えます。
今回はそんなユースケース向けに、元の処理に手を入れずに streaming (逐次) 型で処理を追加する例を見てみましょう。
以前には、シリーズで streaming data 関連の記事 を書いたりもしていますので、よろしければそちらもご覧ください。
Spanner database / table の準備をする
まずは、Spanner 自体の準備をします。
(なるべく安く…) instance と database を作成し、そこに table を作成しておきます。
TESTNAME=hoshy-test
gcloud spanner instances create ${TESTNAME} \
--description="${TESTNAME}" \
--config=regional-us-central1 --processing-units=100
gcloud spanner databases create db1 --instance=${TESTNAME}
gcloud spanner databases ddl update db1 --instance=${TESTNAME} \
--ddl='CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)'
参考 : gcloud spanner databases create | Google Cloud CLI Documentation
念のため確認しておきます。
gcloud spanner databases execute-sql db1 --instance=${TESTNAME} \
--sql='SELECT * FROM Singers'
まだ table に行を入れていないので何も表示されませんが、エラーにならなければ OK です。table の存在は web console でも確認できるので、そちらでもよいです。
Spanner change stream のセットアップ
Spanner には change streams という仕組みが実装されており、データ変更イベントを受け取ることが出来ます。
ここでは document の例にあるものをそのまま使います。
イベントを受けることができるように、対象の table と column を指定して change stream を作成しておきます。実際の運用時でも処理量を減らすために対象を限定しておくとよいでしょう。また、権限管理や負荷分散の観点で metadata database を実データ用のものと分けたほうがよい ようですが、ここでは簡略化します。
gcloud spanner databases ddl update db1 --instance=${TESTNAME} \
--ddl='CREATE CHANGE STREAM ChangeStream1 FOR Singers (FirstName)'
ちなみにイベント関係の製品というと Eventarc もありますが、 Spanner、AlloyDB や Cloud SQL 等では行の追加変更のような細かいものはなく、instance や database の単位でのイベントのみが用意されており、今回の用途には合わないようです。
Pub/Sub のセットアップ
今回は、change stream を受け取ったら、Pub/Sub に送るようにしたいので、そのための topic を作成しておきます。
gcloud pubsub topics create ${TESTNAME}
gcloud pubsub subscriptions create ${TESTNAME}-subs --topic ${TESTNAME}
Spanner change stream を受け取るための処理を準備する
現状は ここ によると、change stream を読みとる方法として 以下の三種類が案内されています。
- Dataflow job
- Spanner API
- Kafka connector
今回はその他の GCP サービスにイベントを連携させることを想定して、それに便利な Pub/Sub へ、Dataflow を通して streaming 送信することにします。もし Kafka の環境がすでにあるようであれば、そこに流すのもよいかもしれませんね。
それにしても、Pub/Sub くらいは直接対応してくれても… と思ってしまいます。Dataflow なり、自前で準備するのはとてもしんどいものです。なんとなくそのうち対応が来たりするかもしれませんね。(そうするとこの記事の半分は意味がなくなりますが 😇)
Dataflow Template
Dataflow job をゼロから作るのは気が重いのですが、ありがたいことにさまざまな用途でそのまま使える template を用意してくれています。今回もそのうちのひとつをそのまま利用します。
Cloud Spanner change streams to Pub/Sub template > Run the template
(ソースは これ や options を見るとよさそうでした)
上記 document にあるコマンド例を使って Dataflow job を deploy します。
一部固定値に置き換えていますので、詳細は document を参照してください。
gcloud dataflow flex-template run spanner2pubsub \
--template-file-gcs-location=gs://dataflow-templates-us-central1/latest/flex/Spanner_Change_Streams_to_PubSub \
--region=us-central1 --num-workers=1 --max-workers=1 --worker-machine-type=n1-standard-2 \
--network=cogo-devenv --subnetwork=regions/us-central1/subnetworks/cogo-devenv-us-central1 \
--parameters=spannerInstanceId="${TESTNAME}",spannerDatabase="db1",spannerMetadataInstanceId="${TESTNAME}",spannerMetadataDatabase="db1",spannerChangeStreamName="ChangeStream1",pubsubTopic="${TESTNAME}"
web console の Dataflow に進み、状態を確認してみましょう。
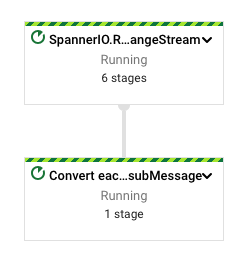
これで一通りの準備ができました。
試す! (ようやく)
Spanner database に変更を入れます。
gcloud spanner rows insert --instance=${TESTNAME} \
--database=db1 --table=Singers \
--data=SingerId=1,FirstName="Marc",LastName="Richards"
想定では、これで change stream にデータが送信され、Dataflow pipeline によって処理されて Pub/Sub にデータが送られているはずです。
Pub/Sub から message を pull できるか確認します。
gcloud pubsub subscriptions pull ${TESTNAME}-subs --auto-ack
データが取得できたでしょうか。結構大きな json data に、様々な情報が入っています。これを parse して目的に応じた処理をする実装をするのも、なかなかパターンが多そうで、テストにある程度時間がかかりそうですね。
参考 : Data change records
以下に、INSERT によって送信された json の抜粋を載せておきます。
{
...
"tableName":"Singers",
"rowType":[
{
"name":"SingerId",
"type":{
"code":"{\"code\":\"INT64\"}"
},
"isPrimaryKey":true,
"ordinalPosition":1
},
{
"name":"FirstName",
"type":{
"code":"{\"code\":\"STRING\"}"
},
"isPrimaryKey":false,
"ordinalPosition":2
}
],
"mods":[
{
"keysJson":"{\"SingerId\":\"1\"}",
"oldValuesJson":"{}",
"newValuesJson":"{\"FirstName\":\"Marc\"}"
}
],
"modType":"INSERT",
"valueCaptureType":"OLD_AND_NEW_VALUES",
...
}
意図したようにしっかり、FirstName の値について報告されているように見えます。
さて、今回の目標は達成しました!
後片付け
作成したものをひととおり片付けます。
gcloud dataflow jobs cancel <job-id>
gcloud pubsub subscriptions delete ${TESTNAME}-subs
gcloud pubsub topics delete ${TESTNAME}
gcloud spanner databases ddl update db1 --instance=${TESTNAME} \
--ddl='DROP CHANGE STREAM ChangeStream1'
gcloud spanner databases delete db1 --instance=${TESTNAME}
gcloud spanner instances delete ${TESTNAME}
まとめ
何も無いところから試すには、いろいろと準備が必要で、手間が多いです。
すでに Spanner を利用している application があってそこに処理を追加する場合は、むしろこの先の追加処理の実装がメインのタスクになりそうです。
この仕組みを使うことで、既存のシステムに変更を入れず処理を追加することができるのが魅力ではないかと思います。スループットの計測や負荷特性までわかるとよかったですが、Spanner に対してそれをするにはお金がかかり過ぎるのでここではやめておきます 🤗
Troubleshoot
Dataflow flex-template run がうまくいかないとき
Cloud Logging を resource.type="dataflow_step" で error が出ていないか確認してみましょう。
たとえば、検証環境では使用していなかったので VPC network default を削除していたのですが、network を明示的に指定しないで実行した場合、これが問題で起動に失敗しました。症状としては gcloud dataflow flex-template run をしてから一秒ほどで Failed になっていました。Dataflow の UI で log も一切出ず、Logging に log が出ているのに気づくのが遅くなりました。
さらにこの network 指定でもハマりました。--network と --subnetwork に分けてそれぞれ名前を指定していたのですがこれではうまくいかず、--subnetwork に path 形式で指定すると受け入れられました。具体的には --subnetwork=regions/us-central1/subnetworks/<subnetwork-name> このような書式を使いました。
また、実行時に使用される service account にも注意が必要です。指定がなければ GCE の default service account が使用されますが、これに必要な権限がない場合はそれを調整するか、または別で必要な権限のみを持たせた SA を用意して --service-account-email で指定しておけばよいでしょう。
なるべく費用をケチろうと --worker-machine-type で f1-micro を指定したときにも起動が失敗しました。メモリ不足とのことで、こういった理由も Cloud Logging にちゃんと出ていて助かります。
